Well, for a long time I don't write a single paragraph in this blog. I really sorry, but my time is quite reduced because I have a little problem on balancing my time between family, work and pgModeler which isn't so easy so I hope you can understand my long periods of silence here. :)
Okay! Now talking about my last work on pgModeler, what I have to say is that a lot of effort was put on it and the result is a more performatic and complete tool which introduces new features in order to make it compatible with the latest releases of PostgreSQL as well bringing improvements to the current capabilities. Since this is an alpha release and brings several changes, despite all test routines, glitches, crashes and bugs are expected so if you stumble on any problem don't forget to report it at Github. Said that, let's detail a few things of this version.
The DTD (document type definition) structure of the database model file has changed in this release. Models created in previous releases will certainly fail to load due to incompatibilities because some attributes in the XML code are not valid anymore on 0.9.2-alpha1. So, before load your database model in this new release, please, make a backup of it and follow the steps presented by the tool to fix the document's contents.
** Table partitioning **
In PostgreSQL, table partition refers to the action of splitting one large table into smaller physical pieces. There're several benefits that we can gain from table partitioning, for instance, improved query performance, separation of data that are frequently accessed from the seldom accessed data and many others (more details here). In previous pgModeler's releases, there was some ways to simulate table partitioning (as well in PostgreSQL 9.6 and below) by using a combination of inheritances and triggers which could be very difficult to maintain in certain situations. So, in this release, the declarative table partitioning introduced by PostgreSQL 10 and improved by the version 11 has been added to pgModeler, making the partitioning easier to create and maintain.
In pgModeler, table partitioning is configured by using three features: the partitioning strategy, the partition keys and through a partitioning relationship. The partitioning strategy or simply partitioning is the mode in which PostgreSQL will handle the data separation in the main table (sometimes called partitioned table) and in its partitions. There're three supported partitioning modes: LIST, RAGE and HASH. The partition keys are a set of columns of the partitioned table or expressions that are used to define the key columns or values used to determine the correct partition to where the inserted data will be routed, for instance. Finally, a partitioning relationship is used to denote graphically that a table is a partition of another as well to configure the partition bounding expression that is used to route the data to a specific partition based on the value(s) in it. The syntax of the bounding expression is tied to the partitioning strategy adopted and has different forms of writing, thus pgModeler helps the users by creating a template expression when a new partitioning relationship is being created.
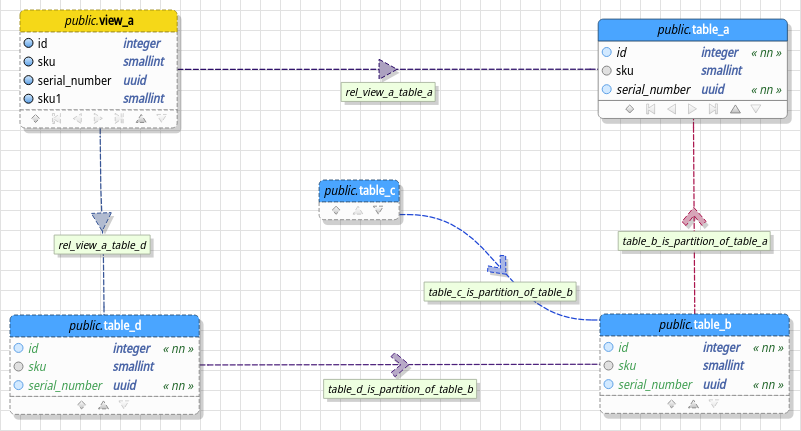
In the image above we have a small partitioning hierarchy created. The relationship between table_a (partitioned) and table_b (partition) is the new partitioning relationship introduced by this release. Notice that it has its own descriptor or identifier: an arrow always pointing to the partitioned table which makes its representation unique among all kinds of relationships. Even the relationship's name label enforces that it is representing a link between a partition and its partitioned or parent table.
Still in the image, in the table properties dialog, the highlighted section contains the partitioning strategy used by table_a as well the partition key(s) (in the grid at the bottom) for the partitioning hierarchy. Now, in the relationship properties dialog, the highlighted area is the partition bounding expression used to define values of the partition key defined in table_a in which will be route to table_b.
The button Generate expression will create a template used as bounding expression. For LIST mode the template is IN (value), for RANGE the expression is FROM (value) TO (value) and for HASH the generated template is WITH (MODULUS m, REMAINDER r). Lastly, the video below shows a more complex partitioning hierarchy by using subpartitions and showing the tool's capabilities of importing partitioned tables from an existing database.
** Attributes pagination and collapsing **
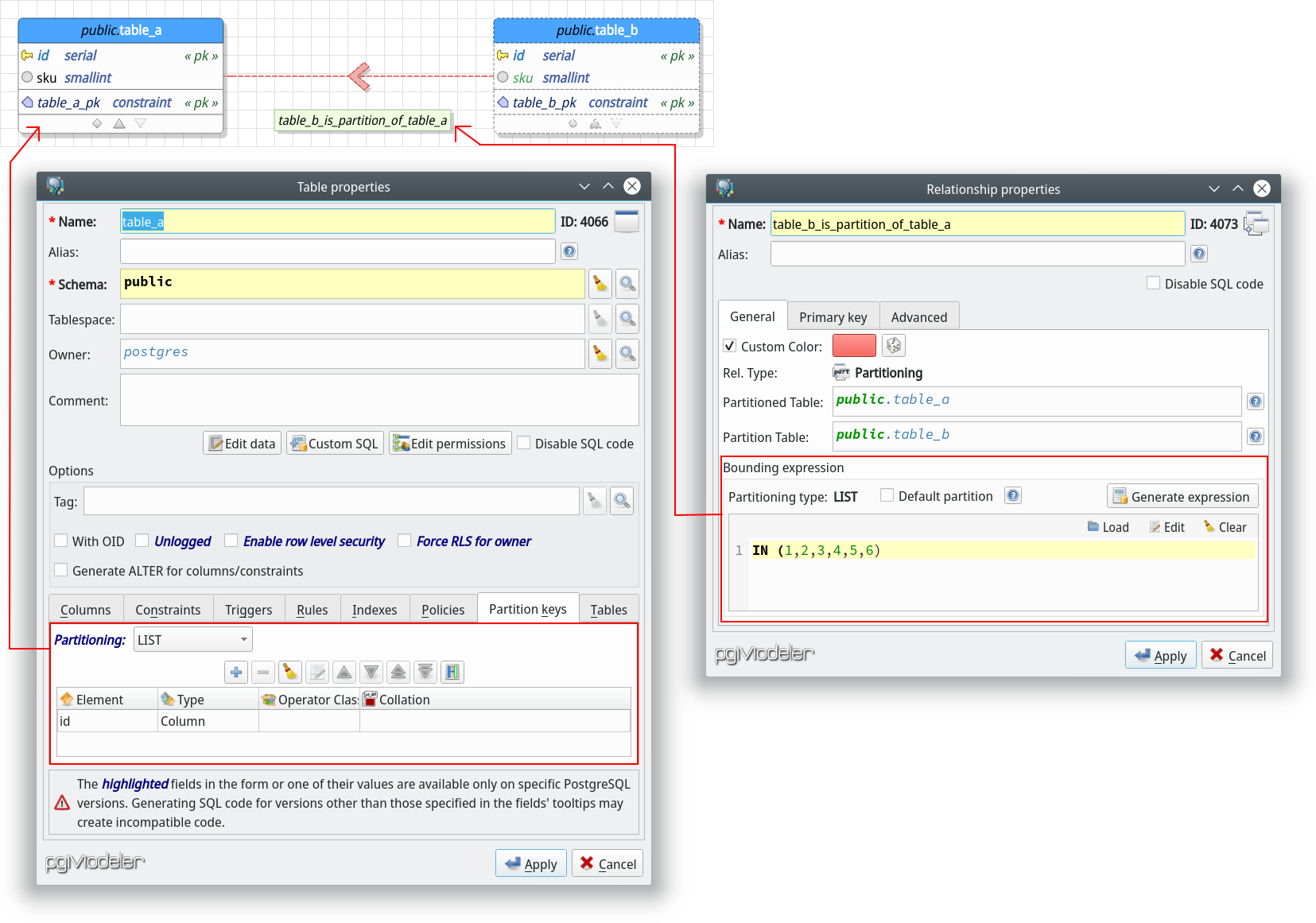
The attributes collapsing allows the user to reduce the size of the tables and views by hiding sections of these objects. This mechanism, requested long ago, can be used to reduce the area occupied by tables and views making the model better to visualize depending on the size of the objects in it. Once collapsed, a section can be expanded back when needed. The collapsing state of any table in the model is persisted to the model file being restored every time the database model is loaded from the filesystem.
In the same logic, which is to reduce the size of objects in the canvas, we have also introduced the attributes pagination feature. This feature is a "less aggressive" size reducer compared to the table collapsing because it simulates the pagination of the attributes. Once toggled the pagination on a table or view, the user is able to navigate through the pages of each section by using the buttons at the bottom of the object. The amount of attributes (columns) and extended attributes (indexes, rules, triggers, etc) visible per page is configurable via General settings. Alike the collapsing, the pagination state of each table and view is persisted to the database model file being restored when the file is loaded. The schema below gives an ideia on how both features work.
Finally, you can toggle pagination or collapse sections of all tables and views just by activating the contexts menu item Paginationor Collapse by right-clicking a blank area on the canvas.
** View columns **
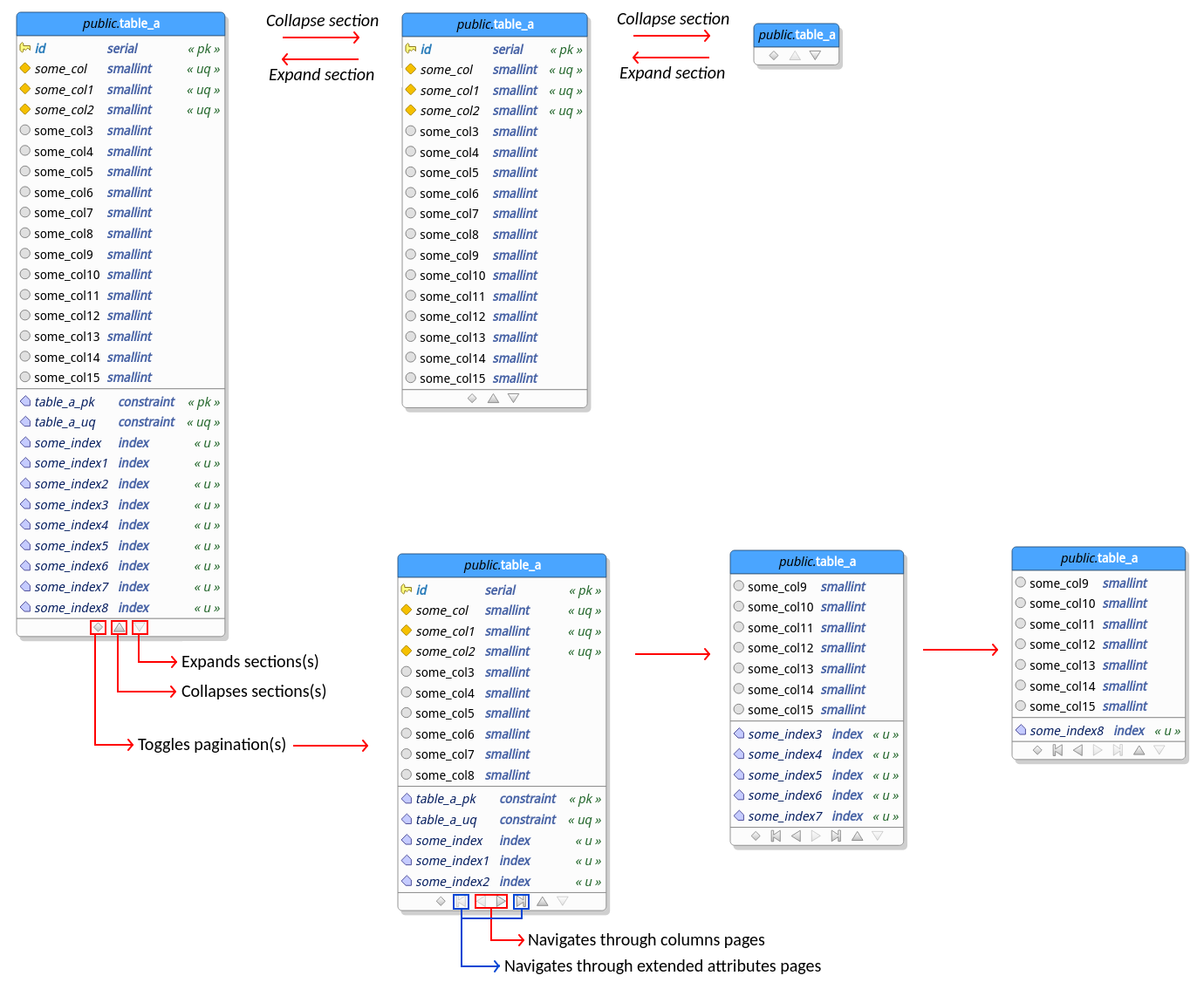
Prior to this release pgModeler wasn't able to determine columns of the views while connecting them to other tables through view references. In certain cases this could cause some difficulty while trying to figure out what columns a certain view could have just by looking at the model. The situation could be worse if you were working on a model generated from reverse engineering. In this case, an imported view would hold only an item related to its whole SQL definition which was completely useless in a database modeling perspective.
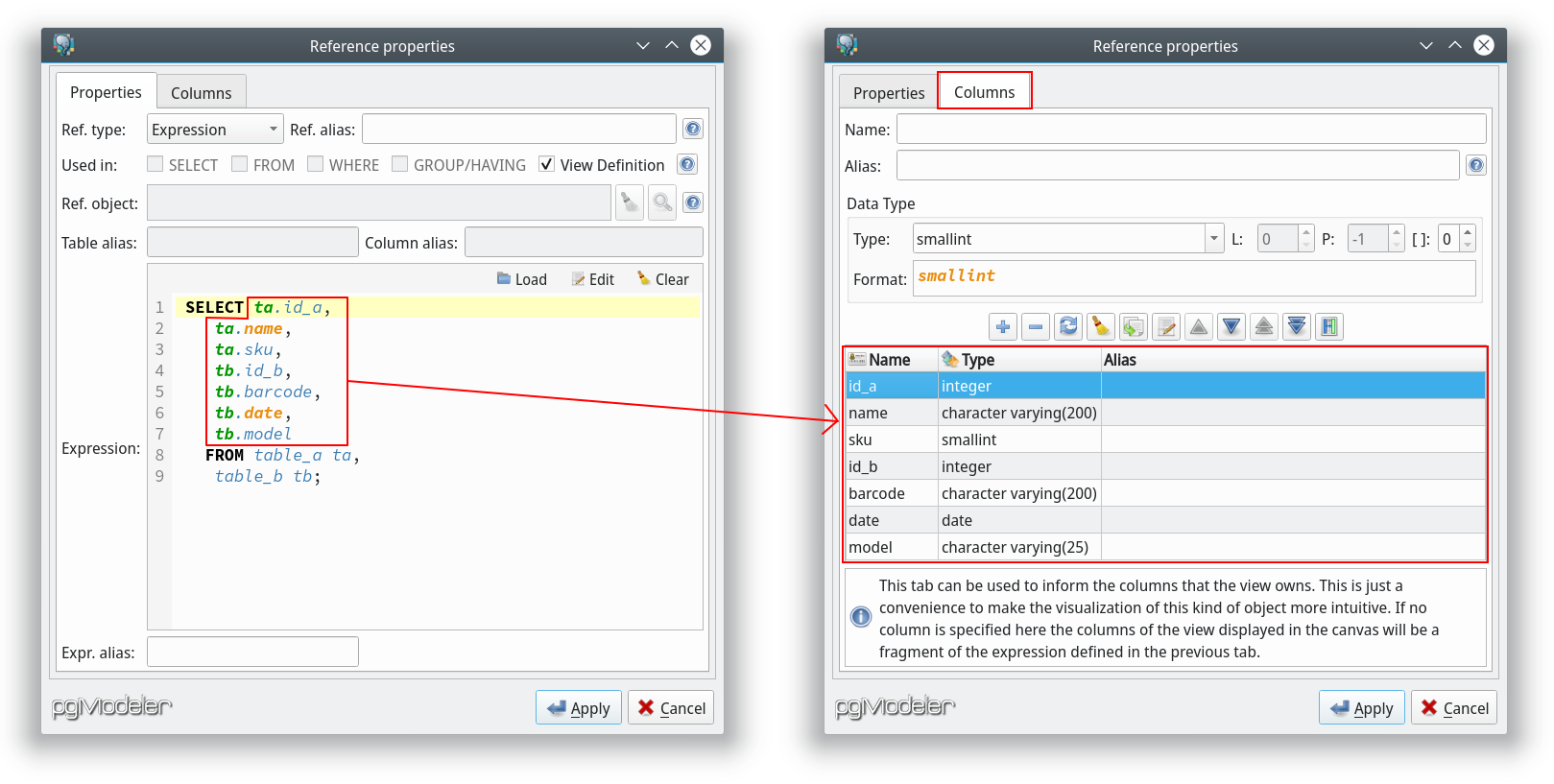
So, after tweaking a little bit the views handling, pgModeler is now able to "guess" which columns a certain view will have just by analyzing its references. Notice that unlike table columns, view columns are read-only objects which means that there's no way to modify them unless you change the related columns on their parent tables. The image below gives an overview on how the view columns are implemented.
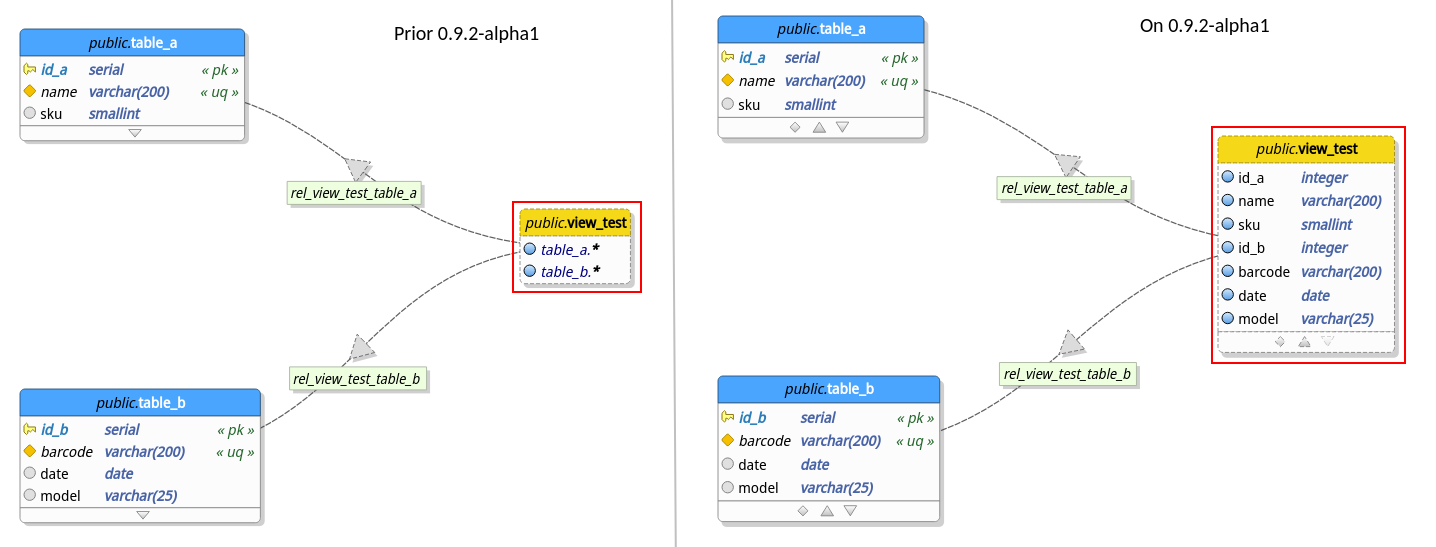
This is a great step but still has its flaws, for instance, views still can't reference the columns of other views as occur with tables this because columns in views are read-only objects as said but this situation can be changed in future releases. Another problem with the current view columns implementation is that columns can't be deduced from expressions, this because in order to be able to generate columns from an expression pgModeler needs to implement some kind of SQL parser so it can extract the columns of the tables listed in the expression. This is a complex task and for now there're no plans to work on it. There's only one exception for this deficiency: you can specify columns manually for an expression if and only if it's being used as the whole view's definition. This workaround was implemented to make possible the importing of view columns while using the reverse engineering process. Of course, in this case, you're free to change the columns of the view as you wish but be in mind that any modification made on them will not affect the SQL code of the view.
** Canvas layers **
Despite all features available to contextualize portions of the model (schemas, tags and fade in/out feature), attending to some requests, pgModeler now supports layers as another way to segment the objects in the canvas. The main goal of this feature is to quickly hide or show objects on a certain layer. This is very useful if you need to work on a small portion of a large model but don't want or don't need to see all objects at once but just the ones you intend to modify at the moment.
Canvas layers can have custom names (except the Default layer) so you can know in which set of objects (or layer, or context, or whatever) you are working on. The layers aren't global which means that each database model can have its own set of layers. The information about layers are saved in the database model file so it can be restored during loading time. In order to make things easier to the user pgModeler will move all objects of a layer being deleted to theDefault layer so the user can select a new layer to move the objects. Talking about changing object's layers you can do that quickly by using the quick action Move to layeravailable in the canvas' context menu. The video below gives a complete example of layers usage.
** Performance improvements **
In its previous versions pgModeler was using lots of graphical objects to represent a single table (or any other database object drawn on the canvas) which, depending on the size of the model, could lead to a massive usage of the memory as well the CPU when storing and drawing them causing slow downs on any operation over the model. In order to give an idea on how things could be concerning, putting all I said in numbers, if we had a table with 10 columns (without constraints) this object, internally, was being constructed using other 40 small graphical objects (like polygons, rectangles, ellipses, lines, text boxes, etc) all grouped in a single object that is the table itself. This situation at a first glance seems completely acceptable but let's force things a bit.
The canvas rendering was working pretty well when handling a relatively small/medium database model containing, for example, 200 tables and 200 relationships. Translating this to numbers once more, a database model containing approximately 26 database objects would produce around 1050 small objects. This was one of the most important bottlenecks of the application. Graphical objects were extremely "bloated". Now, citing a more aggressive example, a database model containing 1670 database objects would produce something around 109630 small objects. This is where the performance was being heavily degraded. It was almost impossible to move two selected tables over the canvas.
Since my two main concerns on pgModeler is performance and reliable code generation I needed to work almost one month to get rid of that issue. In the end, the amount of graphical objects needed to represent a whole database model could be reduced in approximately 38%. In numbers this improvement means that a huge model like that one containing 109630 small items (in previous versions of the tool) now needs "only" 67902 objects to store and draw the whole database model. This is an impressive difference of 41728 objects! The stuttering while moving or zooming objects over the canvas diminished sensibly and I'm really happy with the tool's new overall performance. You can se technical details of the problem and the solution here.
** Miscellaneous **
This version really brought lots of news but detail every single change log entry here could make this post incredibly long. It's not too much to remember that all changes are listed in the project's change long. Said that, I'll mention some of the key enhancements just to give you a hint on how great this release is! :)
Some other new features that we can mention are: the support to OLD/NEW tables aliases while creating triggers; columns in the data manipulation dialog can be toggled in the tab Columns atFilter widget in order to diminish the amount of columns exposed in that form; SQL execution tabs, in Manage view can be added via the shortcut Ctrl + T or by clicking the button ![]() at the top-right corner of that section.
at the top-right corner of that section.
Lots of modifications were done in this version but the majority of them are related to code refactoring or to features that aren't directly accessed by the user. Anyway, there're some of them that we can talk about. The zooming operations over the canvas are now sensible to the amount of turns done in the mouse wheel, which means, turning it quickly causes the zoom operation to perform faster. The database model loading time was improved by avoiding the rendering of tables while the children objects (indexes, trigger, rules, etc) are being added to them. The reverse engineering performance was improved as well by avoiding update the relationships as they are being imported, and many others.
Finally, citing some bug fixes, the application doesn't crash anymore while renaming view's children objects. Also, crashes related to database model closing are solved too. The reverse engineering was improved in several ways, thus pgModeler is producing even more accurate database models. One of the fixes done in the importing process we can highlight is the correct import of user-defined data types when they are being used in form of arrays, e.g., mytype[]. The diff process received some patches as well and now it's smart enough to avoid generating unnecessary/noise commands related to changing types of serial columns to integer and setting their default values to nextval(). Another fix in diff process is the correct detection of columns' comments changes.
Phew! I think that's it... Now, I would like to say that this was an amazing year for me and this project because I had the chance to talk about pgModeler on a PostgreSQL Conference receiving lots of suggestions/contributions there and even more important my work is being recognized around the globe. This is what really makes me happy and proud of pgModeler and the PostgreSQL community, specially, the Brazilian one!
Thus I wish a Merry Christmas and a great new year to everyone! There'll be lot more of pgModeler in 2019. Thanks for reading and don't forget to let your thoughts on the comments section.
See you! ;)
P.S.: If you want the video of my presentation at PGConf.Brasil 2018 you can fill this form so the crew behind the event can send the playlist to you! It worth the effort, believe me! :)
P.S.1: The next year's edition of PGConf.Brasil has its call for papers open. Have you submitted your talk? What you're waiting for!? ;)
Antonio Fernando Vieira De Sousa
December 18, 2018 at 13:29:38
Utilizo Linux Mint (fork do Ubuntu), sua ferramenta é em PHP? ou uma aplicação como o MySQLWorkbench?
Raphael Araújo e Silva
December 18, 2018 at 15:46:38
É uma ferramenta Desktop que possui funcionalidades semelhantes ao MySQL Workbench só especializada em PostgreSQL.
Stephen Knox
January 2, 2019 at 08:10:44
Ola,
Muito obrigado pelo trabalho muito bom!
Just checking, is the new columns tab of the reference properties in the Github repo yet? I couldn't see it on my build in early December, and I can't see much activity here: https://github.com/pgmodeler/pgmodeler/commits/ae32fbb90b0a86d92065bf8b2fe8d986078d6f98/libpgmodeler_ui/ui/referencewidget.ui
Stephen
Raphael Araújo e Silva
January 6, 2019 at 09:37:43
Hi Stephen. Sorry the delay!
Yes, the view columns are already merged into the official codebase. Please, update your code via "git pull" and use the branch "develop".
Thanks!
jwo
February 20, 2019 at 07:48:40
Is there an Atom/RSS feed for this blog? I would love to have notifications (that don't rely on Facebook) when there is a new content :)
Raphael Araújo e Silva
February 21, 2019 at 11:04:39
No. But we can provide it on a evetual site update! :)
John
May 13, 2019 at 08:35:24
Hello! Any ETA for next alpha or beta?
Raphael Araújo e Silva
May 13, 2019 at 16:57:57
Hi! Yes, in two days! :)
Add new comment