Hey there, people!
Despite a little delay, I'm happy to announce another alpha release of pgModeler. This time the tool brings some important improvements on reverse engineering and database model design features. Some other parts of the software have received some patches in order to improve its overall performance and usability. Also, there's an experimental packaging for Linux and many other changes that will be detailed below.
AppImage for Linux distros
One of the major problems I had in previous versions of pgModeler was the deployment on Linux distros because each one has its own way to manage dependencies, libraries, development packages, and so on. For those who can't compile the tool and use the provided official installer or tarball, it can be a pain to use pgModeler on Linux distribution mainly because of incompatibilities between the libraries bundled with the tool and the ones present on the running system. The classical problem is conflicts between pgModeler and the Qt version present on the system. So, after a lot of research, I found the incredible AppImage project. Here's what the AppImage docs say about it:
"AppImage provides a way for upstream developers to provide “native” binaries for Linux users just the same way they could do for other operating systems. It allows packaging applications for any common Linux-based operating system, e.g., Ubuntu, Debian, openSUSE, RHEL, CentOS, Fedora, etc. AppImages come with all dependencies that cannot be assumed to be part of each target system in a recent enough version and will run on most Linux distributions without further modifications."
Basically, AppImages comes to takes away from the developer the burden of guessing which library needs to be bundled with his/her application in order to run flawlessly on the popular Linux distros. It is worth a good reading on AppImage documentation to understand how it works. But, basically, AppImages bundles all the dependencies of the application in an image that most Linux distros can understand as being an application. If you also run macOs will notice that AppImages works almost like application bundles.
For now, AppImages are experimental for pgModeler but despite this fact I got pretty good results running the same AppImage on different distros. In my case, the distros were: openSuse, Kubuntu, Ubuntu, Debian, Mint, and Fedora. If you have a special distro in which you would like to see an AppImage working (if it isn't working already), please let me know.
Managing relationship generated objects
In this new release, pgModeler introduced a way to edit relationship-generated objects. By default, when the user creates a one-to-one, one-to-many, or many-to-many relationship pgModeler will create and lock the objects (columns and constraints) that represent the link between the tables. This is done because the tool needs full control over those objects in order to propagate name changes and other attributes making repetitive operations of linking tables via foreign key constraints more quick and pleasant. This feature is called column propagation.
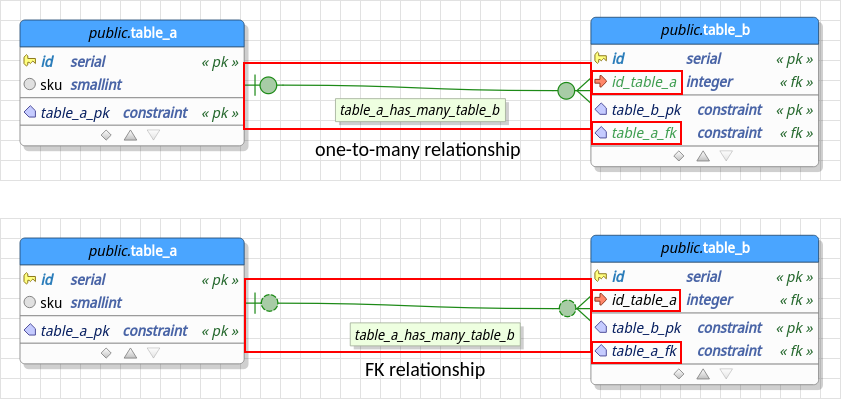
The drawback of those objects' locks is that the user isn't able to change their attributes which, in some really specific scenarios, is a bad thing. Thinking of these specific cases, one now is able to "convert" the relationships in such a way that the locks are removed and the user is free to change the columns and constraints structures. Basically, converting a one-to-one or one-to-many relationship will cause the detachment (unlocking) of the objects that represent the relationship generating an FK relationship instead. Such conversion feature already exists for one-to-many relationships. The only drawback of converting a relationship is that you'll lose the column propagation feature for any converted relationship, being up to you to change any of the attributes of the objects that are related to the linking between tables.
The image below demonstrates the same relationship before and after the conversion. In the first case, the relationship is still an ordinary one-to-many being the column id_table_a and the constraint table_a_fk the objects locked and managed by it. After the conversion, which is triggered by a right-click on the relationship and choosing Convert, an FK relationship is created in place and the objects id_table_a and table_a_fk are now unlocked for any kind of modification.
Improved FK relationships semantics
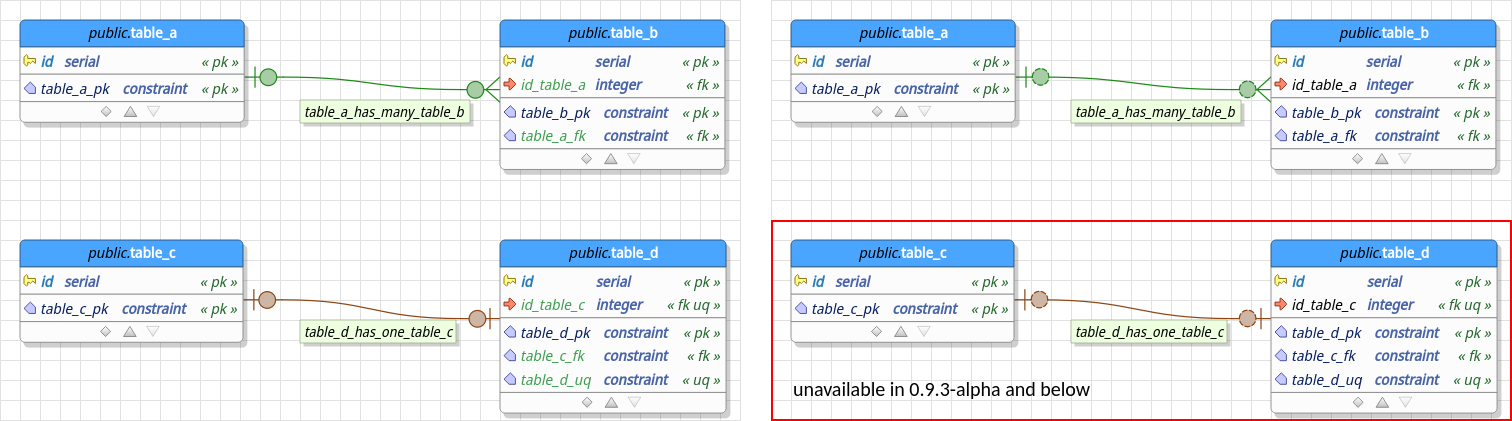
Prior to this release, FK relationships were rendered in a generic way no matter the entities' cardinalities. For example, if you had two FK relationships representing one-to-one and one-to-many relationships they were rendered like the arrangement at the top-right side of the image below. This could lead to loss of semantics and confusion to those who would use the database model for documentation purposes or code generation because the model wasn't expressing what the generated SQL code represented. So, in order to fix this problem, pgModeler now try to guess what's the correct semantics of an FK relationship and renders it as a one-to-one or one-to-many depending on how the columns, not null, foreign key, and unique key constraints are configured. Of course, this isn't a silver bullet and false-positive detections may occur but in almost all cases the rendering will represent the real semantics of the linking between tables.
Reverse engineering filters
An important feature introduced by the 0.9.3-alpha1 and that I'm pretty sure will help lots of people is the objects filtering in the reverse engineering dialog. Now the user is able to provide filtering patterns that force pgModeler to list only those items matching the defined criteria. This is really useful when you need to import just a small set in a huge database.
In older releases, the user was able to work with subsets of the database but there was the need to list all objects first and then select only those to be imported. This could consume an unnecessary time. By design, reverse engineering is not a quick operation since it demands lots of queries on the PostgreSQL's system catalog, and depending on the size of the database those queries could take a lot of time to retrieve all objects to list and only after that allow the user to select the desired ones. So thinking of optimizing this process of listing and selecting objects the filters were introduced.
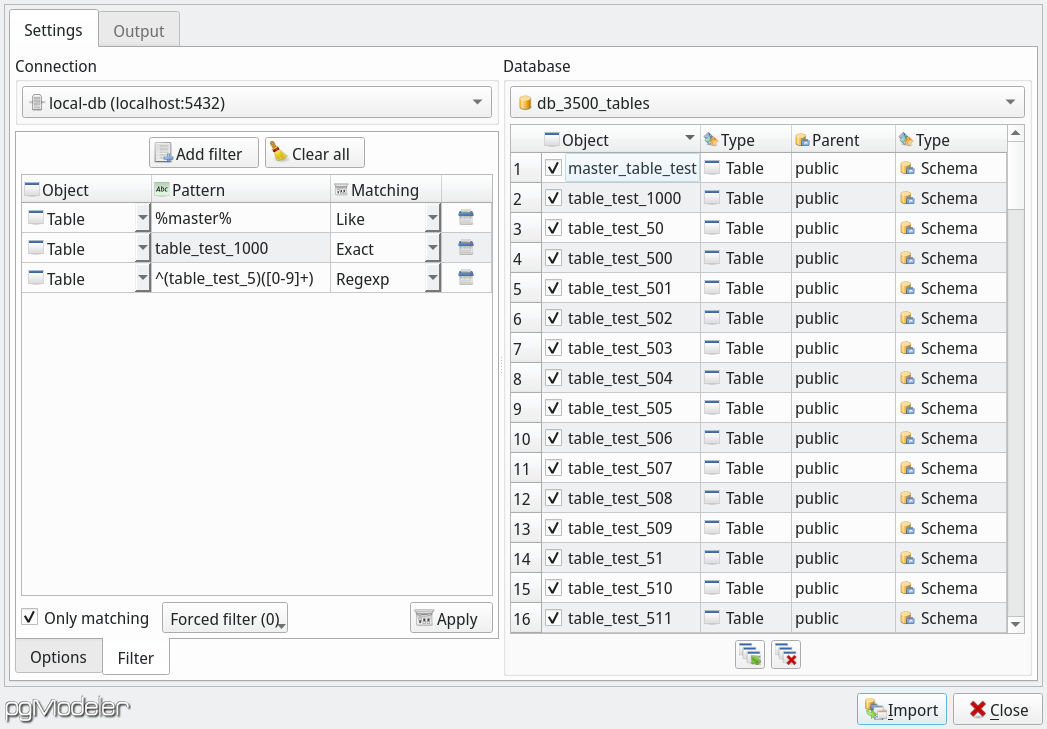
The image above shows a sample database containing ~3500 tables (and twice the number of constraints). So listing everything first before selecting, let's say, a hundred objects was a waste of computational resources. So, here's where the filters enter. In the image, there're three filters specified, and once applied they could retrieve only 111 in just a small fraction of the time that it could take bringing all the thousands of objects thus to select only just a few.
In the filter widget on the image above we have the Add filter and Clear all that are used respectively to create a new filter and remove all the ones already configured. In order to erase a filter individually you can click the icon ![]() . The column
. The column Object in the filters grid indicates the object type to which the filter in that row applies. The Pattern column is a string that is matched against the names of the objects. The Matching is the mode in which the pattern is compared with the names. There're three possible modes: Exact, Like and Regexp. They are basically the indicator of what SQL matching will be performed when querying the system catalog. Said that the Exact is the operator =, the Like refers to the ILIKE operator, and Regexp is the alias to the regular expression matching operator ~*. If you are a PostgreSQL experienced user you probably have perceived that, except for Like matching, all comparisons are case insensitive mode. This behavior may be adjusted in future releases depending on the users' feedback.
Additionally, the filtering counts with extra options in order to refine the retrieved objects set. The first one, Only matching, will cause only objects strictly matching filters to be listed. The default behavior of the filters is to bring only the objects matching the filters and all others that have no filter configured. In order to clarify, in the sample image, if Only matching, was unchecked all other objects like sequences, views, schemas, functions and so on would be listed together with all tables matching the filters.
The button Forced filter (n) is a special filter option that causes table children objects (constraints, indexes, triggers, rules, and policies) to be listed when there's the presence of at least one table/view/foreign table filter. This is useful, for instance, when you need to import just a small set of tables and their peers (defined by foreign keys). It's important to say that this special action is taken only for the tables matching the filters. Clicking the button will raise a menu containing the children objects types that you want to force the listing. Once selected an item in that menu the (n) suffix on the button's label will be updated with the number of children objects being forcibly filtered. Once all filters are set you can click Apply and see the magic happening!
Finally, the reverse engineering filters are also available on the pgModeler command-line interface (pgmodeler-cli) . The options --filter-objs, --only-matching and --keep-child-objs are the CLI equivalent options to the ones presented in the reverse engineering dialog.
PostgreSQL 12 generated columns
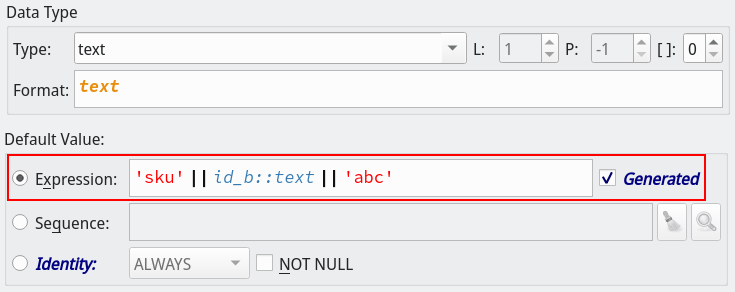
The new PostgreSQL 12 generated columns is now available on pgModeler. A generated column, according to PostgreSQL docs, "is a special column that is always computed from other columns. Thus, it is for columns what a view is for tables." Currently, only stored generated column is supported and this one "is computed when it is written (inserted or updated) and occupies storage as if it were a normal column". Besides the support to the creation of generated columns in the database model design, pgModeler also introduces the importing as well as the diff of this kind of object. This way, it covers these new improvements of the RDBMS.
Miscellaneous fixes and changes
On the bug fixes side, some crashes were eliminated in different portions of the application. Also, the relationships are now using correctly the provided global name patterns. Additionally, some fixes on the system catalog queries used by pgModeler when running import and diff brought some performance gain on these operations. There're many other changes and fixes and you can check the complete list related to this version in the CHANGELOG.md.
Don't forget to give some feedback about this release!
Until next time! ;)
Add new comment