
Oh boy! I thought this moment would never come, but it's finally here! pgModeler 1.0.0 is a reality, a dream of seventeen years, and a huge effort to deliver a useful product to the open-source community. With this announcement, I declare retired pgModeler 0.9.4, which implies that no more support will be provided to it. From now on, my focus will be completely on 1.0.0. This release brings tons of changes, fixes, and new features compared to 0.9.4 and I already consider the best pgModeler ever! I'm really looking forward to receiving all kinds of feedback. :)
So let's not waste more time... Here go some key changes and improvements related to this version!
Before you start using 1.0.0!
If you have installed pgModeler 1.0.0-alpha before and skipped versions 1.0.0-alpha1 and above you may get the error "Error while interpreting XML buffer at line 0 column 0. Message generated by the parser: No declaration for attribute partial-match of element group." right before pgModeler quits during its startup.
This error occur due to an attribute of the syntax highlight files which was dropped. The solution is to manually erase the files *-highlight.conf in your user's local storage where pgModeler settings are saved: /home/(user)/. config/pgmodeler-1.0 (Linux),C:\Users\(user)\AppData\Local\pgmodeler-1.0 (Windows), /Users/(user)/Preferences/pgmodeler-1.0 (macOS). After erasing the files, start pgModeler again so the erased files can be created again by the tool.
Codebase moved to Qt 6
It gave me some headache but now pgModeler is fully compatible with Qt 6, taking advantage of all advances that this major framework version brought. To be more specific, the code builds fine on Qt 6.2.x, 6.3.x, and 6.4.x. The main challenge, which took more time, was to move the huge amount of deprecated code related to Qt 5.15.x to the newer API introduced by Qt 6 without breaking things. There is still some work to do to finish the full migration but I can say for sure that the current state of the code is pretty stable and works satisfactorily well.
Surprisingly, after moving to Qt 6, the code still builds on Qt 5.15.x but bear in mind that there can be backward compatibility breaking at any time as soon as new features are introduced to Qt 6 exclusively and they are used by pgModeler. Due to the amount of time that pgModeler takes from me, I don't intend to make the code work on both Qt 5 and 6. My goal is to make the code Qt 6 compliant only!
Goodbye PostgreSQL 9.x and hello PostgreSQL 15!
Dropping PostgreSQL 9.x support was delayed a lot of times since the launching of PostgreSQL 10, so I decided that during the development of pgModeler 1.0.0 the support for discontinued versions of the RDBMS would be completely dropped, and that was done. Honestly, it was a kinda relief for me because keeping a code base that embraces PostgreSQL 9 to 15 is a huge challenge because there are lots of syntax nuances that I need to keep track of, which causes code complexity to increase. Furthermore, PostgreSQL 9.x is gradually being ditched while modern versions are being quickly adopted, so it doesn't make sense to make pgModeler support such an old version of the database system since it is not maintained anymore by the community.
Being said that, from now on, pgModeler will not generate code for PostgreSQL below version 10. Anyway, you still can connect and handle table data in old PostgreSQL servers with a minimum compatibility mode which can be activated in the general settings (see the image). Anyway, bear in mind that this option doesn't guarantee flawless execution of operations that depend on newer database servers. Also, keep using legacy versions of the database system and even of pgModeler may lead you to security issues and critical bugs that may cause you a lot of headaches, so always upgrade your PostgreSQL and pgModeler installations when possible! ;)
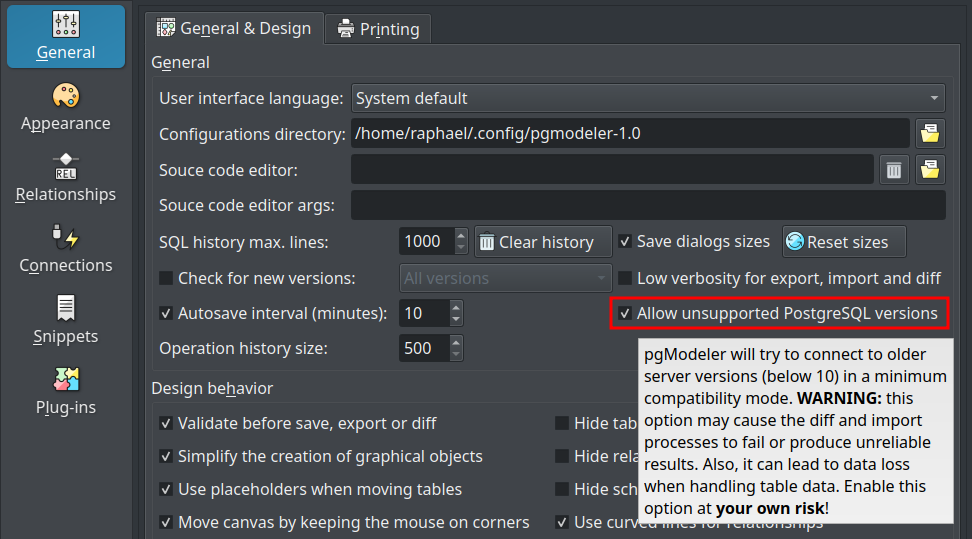
Removing PostgreSQL 9.x support opened up the path to work on PostgreSQL 15. So, some patches were applied to pgModeler in order to make PostgreSQL 15 the default version used by the tool as well as to adjust some catalog queries used by the SQL tool and the reverse engineering feature so it can correctly connect and retrieve information from the system catalogs specifically on that RDBMS version.
Redesigned user interface
pgModeler 1.0.0 brings a refreshed and responsive user interface with new and clean icons, bigger UI elements, a dark theme, and a new project logo. All that focuses on bringing more visual comfort while using pgModeler mainly for extended periods. This is the first of many iterations of UI improvements I want to implement so we have an even more enjoyable tool to work on! But the results presented by 1.0.0 are pretty stunning and pleasant, I really liked how pgModeler looks now!

Dark theme support
One of the most frequent complaints about pgModeler was the lack of a way to use it on systems with dark themes. In fact, pgModeler was not designed initially for that purpose having all styles configured with light colors. So if a user tried to bypass this limitation the result would be disastrous. So, for pgModeler 1.0.0, I had promised that dark themes would be supported and that was done!
Before working on the dark theme support itself, it was needed to move all the options related to color settings from the section General to Appearance. Once moved all the settings to the new place, it was time to glue everything together and add the ability to switch the UI colors between different color schemas, thus, the basic theme support was created.
So, to apply the desired theme, you can choose a value in Theme, under the group User interface, which can be System default, Dark, and Light. The last two values are self-explanatory, but the System default is there for a reason: it allows the user to use the global (system) color theme instead of the color schemas defined by pgModeler. Using the system default theme also allows you to set a color schema (dark or light) for syntax highlight fields so the character colors can combine with your system's theme. This is a small workaround until the users have the ability to create their own themes for the tool.
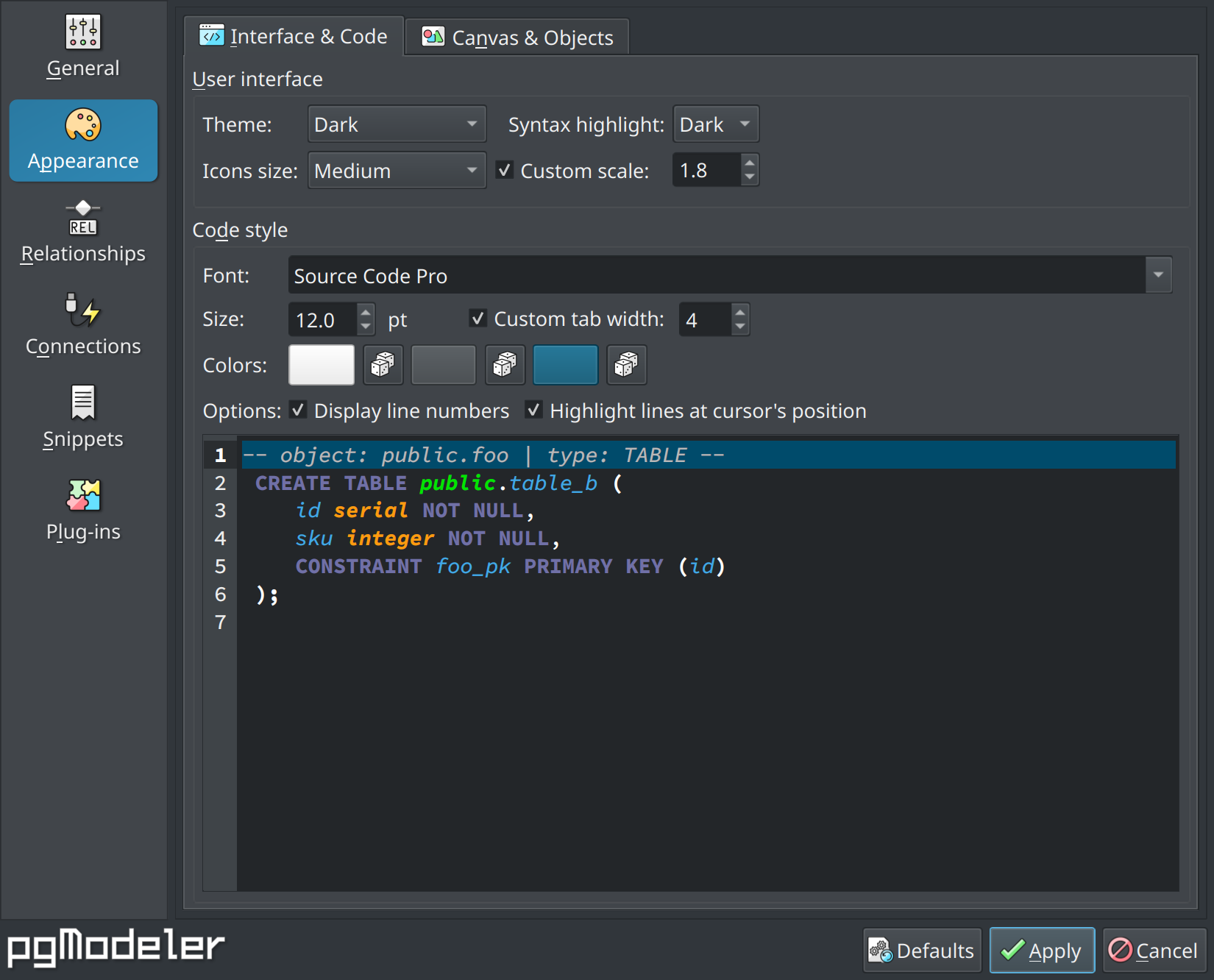
Basically, color themes in pgModeler contemplate UI elements (buttons, input fields, frames, and so on), syntax highlighting settings, and canvas colors (grid colors, canvas color, object colors, etc). Putting everything together was a bit tricky but the result was pretty cool! There are only two downsides related to this new feature:
-
Configuration files created on pgModeler 0.9.4 and below are not compatible anymore. So, in the first run, pgModeler 1.0.0 will try to migrate relationships and database connections settings when finding a previously installed pgModeler 0.9.x in the system. The other settings are all replaced by the new structure introduced by 1.0.0, so, unfortunately, you'll have to tweak everything again.
-
As said previously, there is no support for user-defined themes, yet... But the idea is to introduce an interface so the user can create themes as easily as they design their database models! :)
Below, we have a small comparison between light (classic) and dark themes. Now, the dark theme is the default that you'll see when starting 1.0 for the first time or restoring the settings to their defaults.
Custom icons sizes and UI scale factor
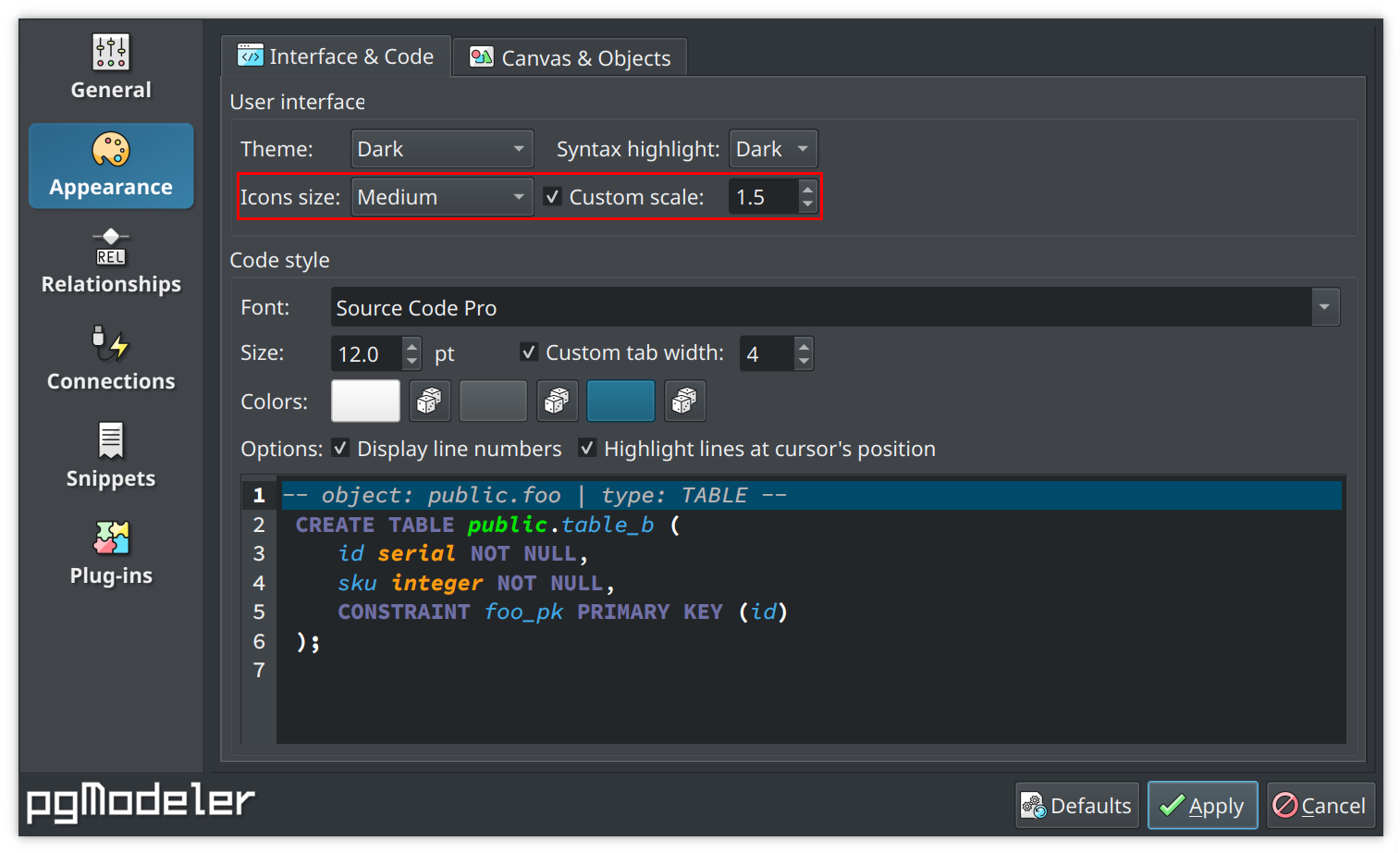
After releasing the revamped UI during the development of pgModeler 1.0.0, the major complaint about the new interface was the size of icons, buttons, and other widgets on small screens. Since the main goal of this project is to provide flexibility and freedom to the user while using the tool, I decided to make lots of adjustments to the forms and other widgets to diminish the occupied screen space. Still not satisfied, I decided to go further and added the ability to change icon sizes and the whole user interface rendering factor. So, in the Appearance settings, one can set the icon sizes on-the-fly using the dropdown menu Icons size. Now, to change the whole UI rendering factor, the user can set a value between 1 and 2 in Custom scale factor to increase or decrease the size of the entire UI. This option requires restarting pgModeler so the new factor can be applied. Note that the use of custom scale factors varies from system to system due to the nuances of each window management subsystem and how the Qt framework communicates with them, so, for example, using 1.5 as a scale factor has a different effect on Windows, Linux, and macOS. By default, the system scale factor is used by pgModeler.
Improved magnifier tool
The magnifier tool is one of the least known features of pgModeler but can help you a lot when working with densely populated database models. The magnifier tool, triggered by F9 in this new version, helps you to navigate through a zoomed-out model while highlighting (in normal zoom factor) a small portion of the model where the mouse cursor is while you can interact with the objects in the magnified area as you would do in the entire database model in a normal view, like selecting multiple objects and even triggering the popup menu to handle objects.
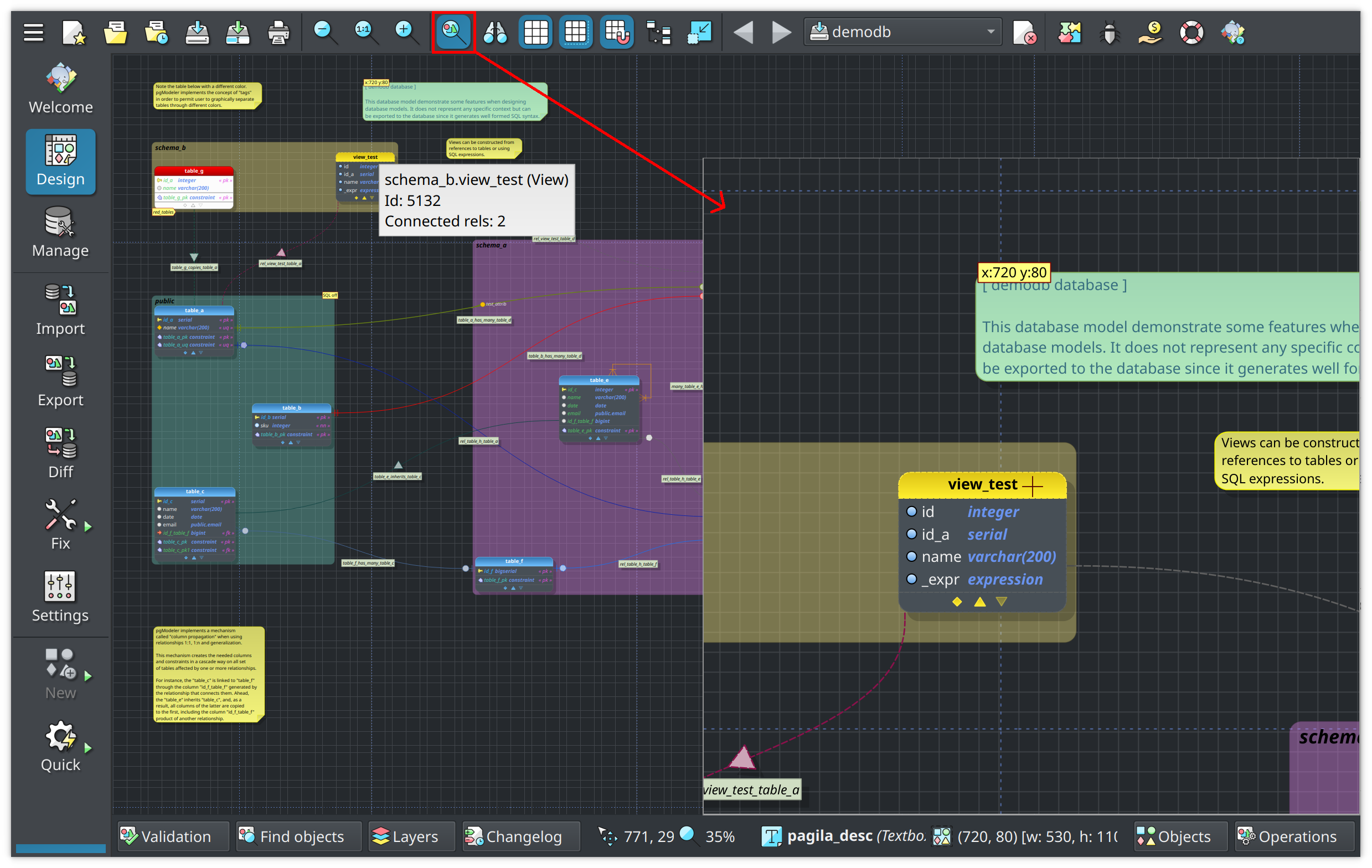
Scale factors when printing models
Another source of complaints in previous versions of the tool was the lack of a way to print database models in a few pages. That was happening because pgModeler was always sending the model to printing in the default scale factor (100%) causing excessive use of paper. So, to workaround that issue, a small patch was applied in such a way to make pgModeler apply a scale factor before sending the model to the printer. Basically, when activating the printing operation, pgModeler will consider the current zoom factor and reproduce it in the printed document.
This behavior needs to be activated before the printing starts, so, make sure to hit Ctrl+K or check the icon ![]() in the top actions bar. Thus, pgModeler will stop resizing the page delimiter lines when the zoom factor changes to a value below 100%. This way, the user can position more objects in the area delimited for one page. The behavior is restored to the default (no print scale factor) when the zoom is equal to or above 100%. The animation below demonstrates how this feature works.
in the top actions bar. Thus, pgModeler will stop resizing the page delimiter lines when the zoom factor changes to a value below 100%. This way, the user can position more objects in the area delimited for one page. The behavior is restored to the default (no print scale factor) when the zoom is equal to or above 100%. The animation below demonstrates how this feature works.
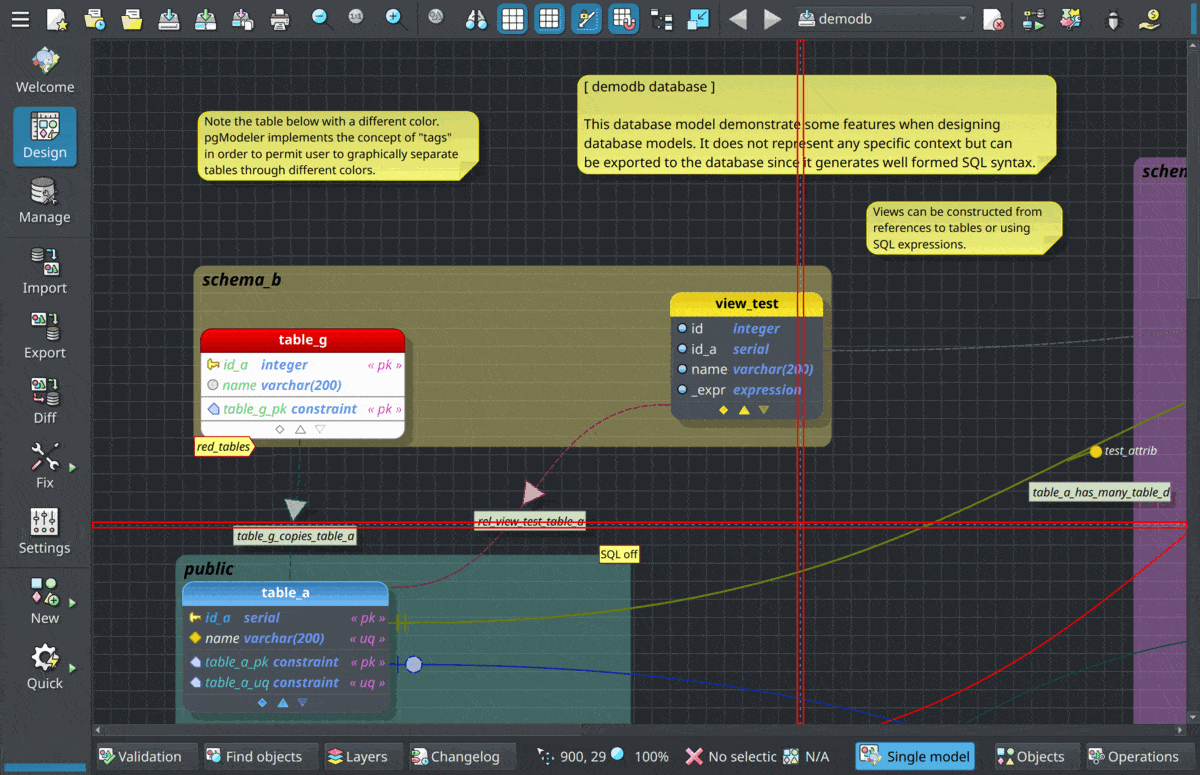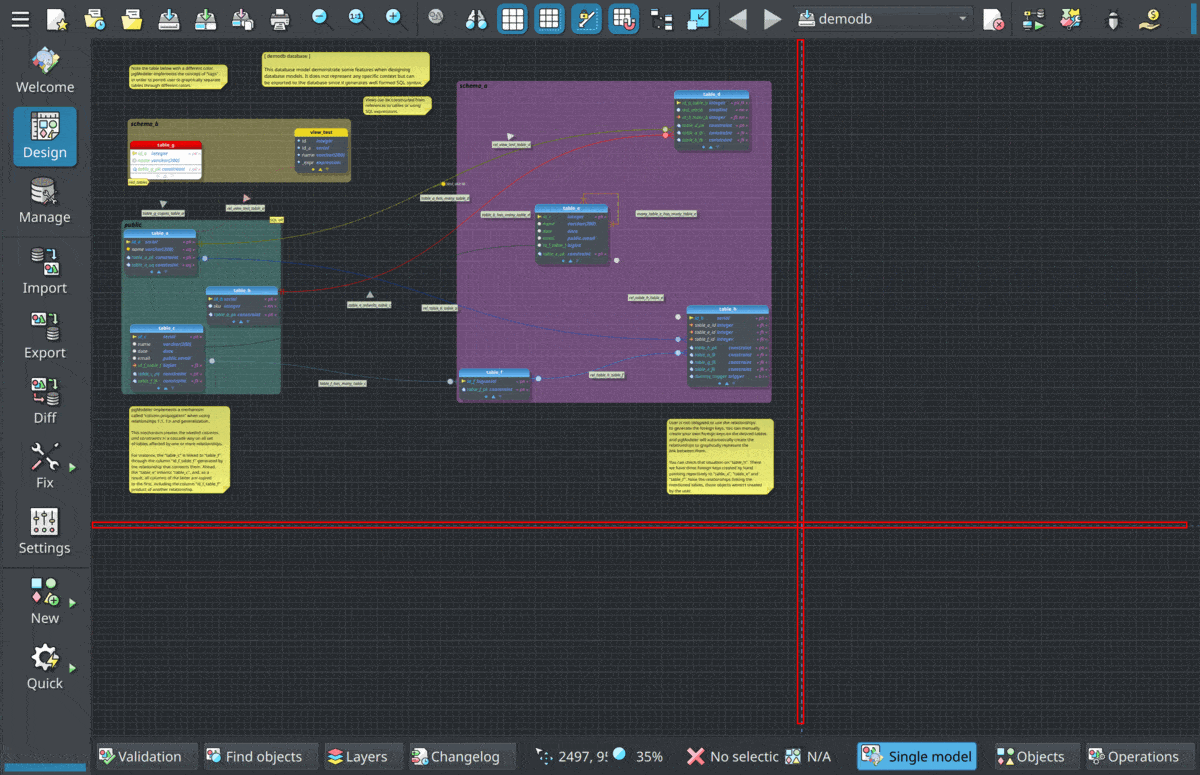
Improved columns/constraints propagation mechanism
The columns/constraints propagation mechanism implemented by relationships is really useful when you need to quickly create relationships between tables without going through the tedious process of adding columns and foreign keys manually. But, to make this mechanism work automagically a lot of code was put on it which increased its complexity, and where there's a high level of complexity there's a high probability of having bugs. One of the most annoying problems with this feature was that in some very specific circumstances, columns and constraints created by the relationships started to disappear or lose their custom position in the table. So, after investigating and understanding what was happening I dedicated a good time to rewrite the whole objects' propagation feature, creating a more simple mechanism that produced the desired results. As a bonus of the refactoring, pgModeler now loads database models a bit faster than the older versions!
Rewritten CSV parser
The previous routine used to handle CSV files in pgModeler was pretty complex and not so effective, so I decided to rewrite it from scratch using as a reference nothing less than the RFC 4180 which details how a CSV must be constructed. That move made a great difference in the loading speed as well as the reliability when working with CSV because pgModeler is now capable of parsing files generated by third-party software easily which improves the interoperability between tools, and, consequently, the users' productivity.
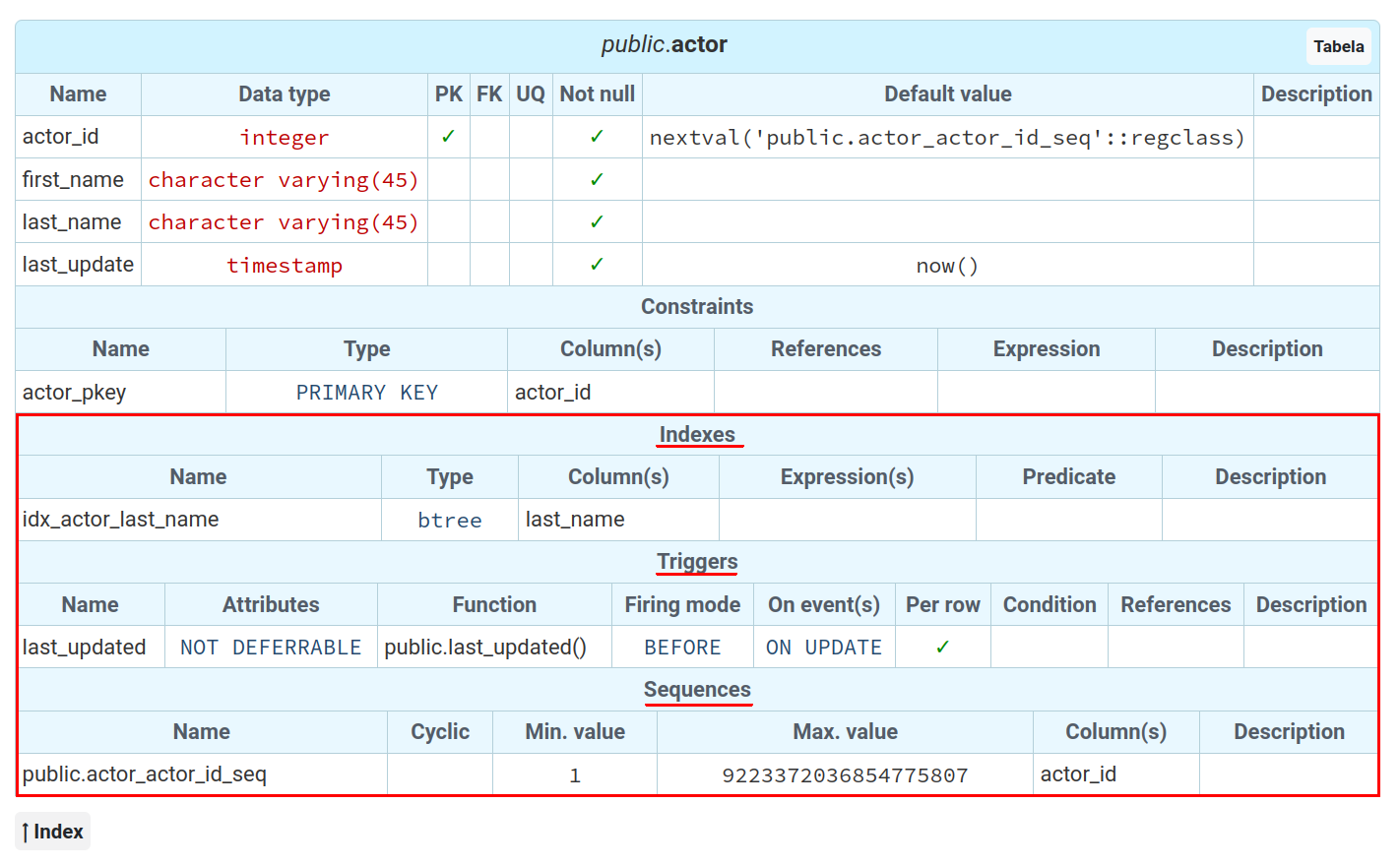
New kinds of objects in the data dictionary
The data dictionary received some patches and is now capable of adding information about indexes, triggers, and sequences related to tables, foreign tables, and views. This improvement makes the generated dictionaries more detailed enriching the database documentation. These objects are automatically added to the tables' dictionaries, so there's no way to avoid the generation of their information grid. Anyway, I'm still planning to add a switch in the data dictionary generation that toggles the inclusion of these objects in the grids, for those who maybe think that the data dictionaries would be polluted with extra (and somehow unneeded) information. Just leave your thoughts in the comments sections so I can adjust this feature in the next releases.
Generate split SQL code in CLI and GUI
Since pgModeler 0.9.4-alpha1 pgModeler offers the generation of split SQL code. In 1.0.0, this feature was improved in such a way to expand the possibilities of code generation for each object. This feature already existed for some time and was "hidden" in the source code visualization form. After some users' requests, I've made some patches and included the code generation mode in both CLI and GUI export operations. The purpose of this feature is to generate the whole chain of SQL code that correctly creates a single object. This is useful mainly in test environments or if the user needs to deploy SQL code in a different way than pgModeler does. There are three code generation modes: Original, Original + dependencies' SQL, and Original + children's SQL. Below, all three modes are exemplified in the source code preview form.
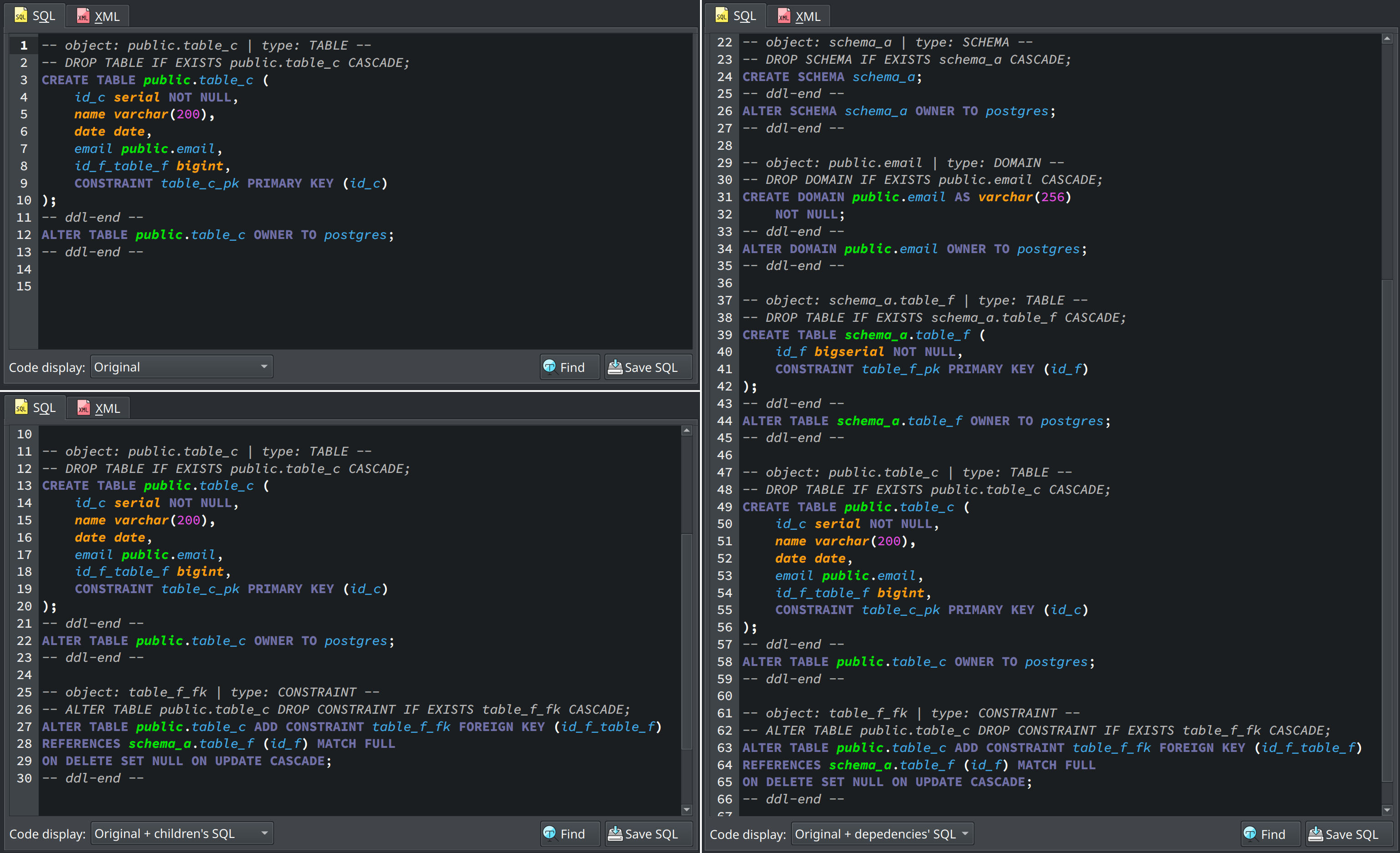
The Original mode, as the name suggests, generates only the original SQL code of a single object without any additional code attached to it. Original + dependencies' SQL generates the original code including all dependencies needed to properly create an object. Now, Original + children's SQL generates the original code including all children's SQL code. This last option is used only for schemas, tables, foreign tables, and views.
In the image below, the same options are displayed in the model export form. You can select the code export mode by checking the option Split, which causes the export process to save the SQL code of the objects in separate files, each one per object, and taking into account the export mode selected in the combo box.
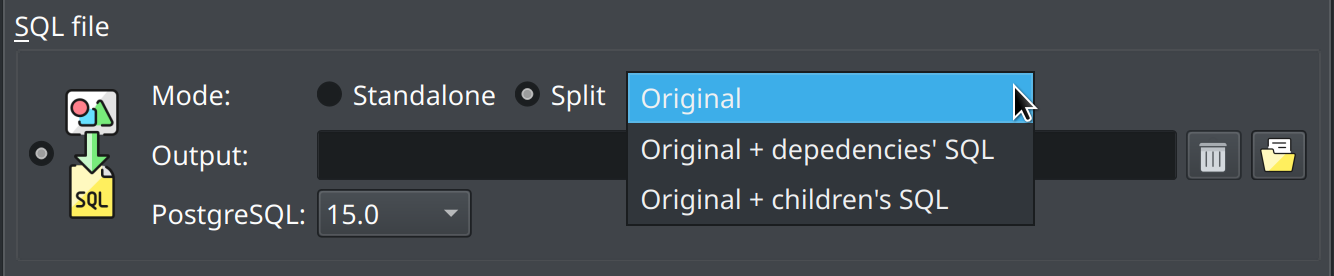
Now, in the command-line interface, the split code generation differs slightly from the GUI. First, you have to specify the output directory through --output, use the export to file operation --export-to-file, turn on the split code generation via --split parameter, and then adjust the code generation using --dependencies or --children. If none of --dependencies or --children is specified then the code generation defaults to Original like in GUI.
SQL file export options: -sp, --split The SQL file is generated per object. The files will be named in such a way to reflect the correct creation order of the objects. -ds, --dependencies Includes the object's dependencies SQL code in the generated file. (Only for split mode) -cs, --children Includes the object's children SQL code in the generated file. (Only for split mode)
Below are some examples of how to call the CLI correctly when using the split code generation:
pgmodeler-cli --export-to-file -if demo.dbm -of /home/user/demo_split --split
pgmodeler-cli --export-to-file -if demo.dbm -of /home/user/demo_split --split --dependencies
pgmodeler-cli --export-to-file -if demo.dbm -of /home/user/demo_split --split --children
AppImage changes
Since this project moved to Qt 6, the provided AppImages are not using older Qt versions anymore. They are being packaged using the latest framework version. I really like the idea behind AppImage, which is mainly focused on supporting older Linux distros via self-contained applications. But being a multiplatform software developer I have to follow all the advances in the other systems. This is always a big challenge because we have to balance backward compatibility and introduce new features via a more modern codebase. Of course, this can always change once older Linux distros start to support the Qt versions adopted by this project, so compatible AppImages can be generated for them.
Exclusive features for the paid version of the tool
It's no secret that like any other open-source project, pgModeler needs financial support! This project lives until today thanks to those who helped with suggestions, criticisms, and, especially, those who believed in its potential and put their money into it. This kind of recognition that makes me work on it since 2006. So, thinking of some kind of reward for the financial supporters, I decided to create exclusive features for the paid version of the tool that will be released from time to time as they are requested. The first round of exclusive features brings three ones that were used, in the first place, to validate the new plug-in development interface, and, of course, to add interesting features to pgModeler to make it even more productive. These extra features are explained in the next sections.
Quick object edit plug-in
The quick edit plug-in, triggered by Ctrl+1, allows one to search for the desired object and open the related editing dialog without the use of mouse clicks. This is a well-known feature on many IDEs, and arrives in pgModeler to improve the user experience, especially for those who prefer a keyboard over a mouse when working with object editing.
Split database model format plug-in
This plug-in introduces a new file format to store database models called split database model (.sdbm). It was designed to improve the version control of model files by saving the XML code of the objects in individual files. This way, it is easier to track the changes made in each database object when the model is handled by several people in a team. For now, pgModeler only saves and loads the split database model. For future improvements to this plug-in, a git integration is planned so the user doesn't need to use external tools to commit changes in the model. Below, is an example of how the split database model is arranged:
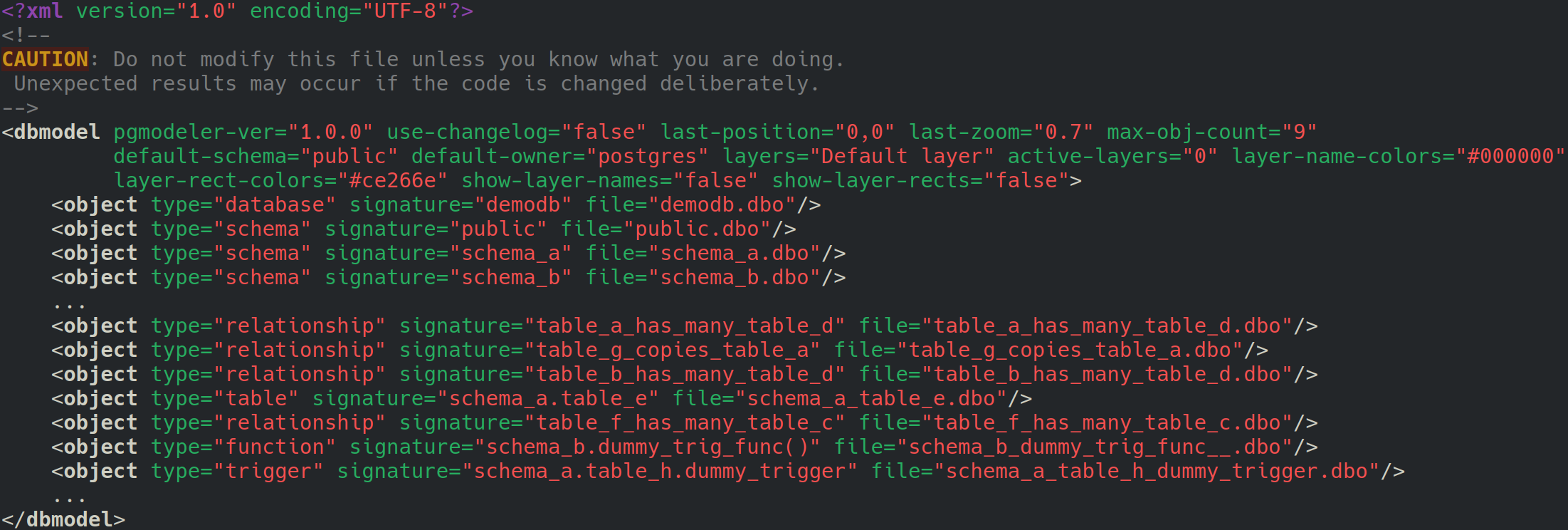
The .sdbm is a variant of the classic .dbm file where some metadata of the database model are stored with the difference that in this file is that instead of having all objects' XML code attached there are references to database object files .dbo which in turn store the XML code that defines each object. Each dbo file is categorized and saved in the folder related to the database object type. For example, the database definition is stored in the file demodb.dbo in the subfolder database. The table schema_a.table_e is saved in schema_a_table_e.dbo in the folder table, and so on. The following image shows an example of the demodb sample model saved in split mode.
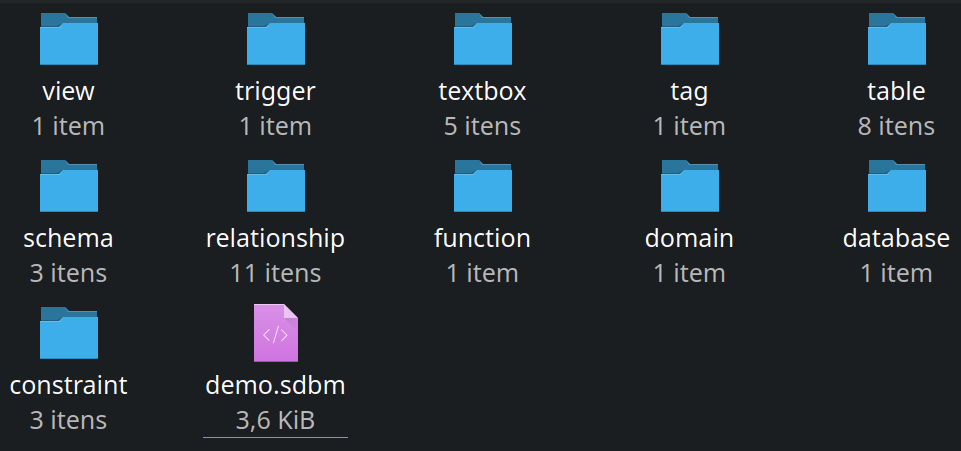
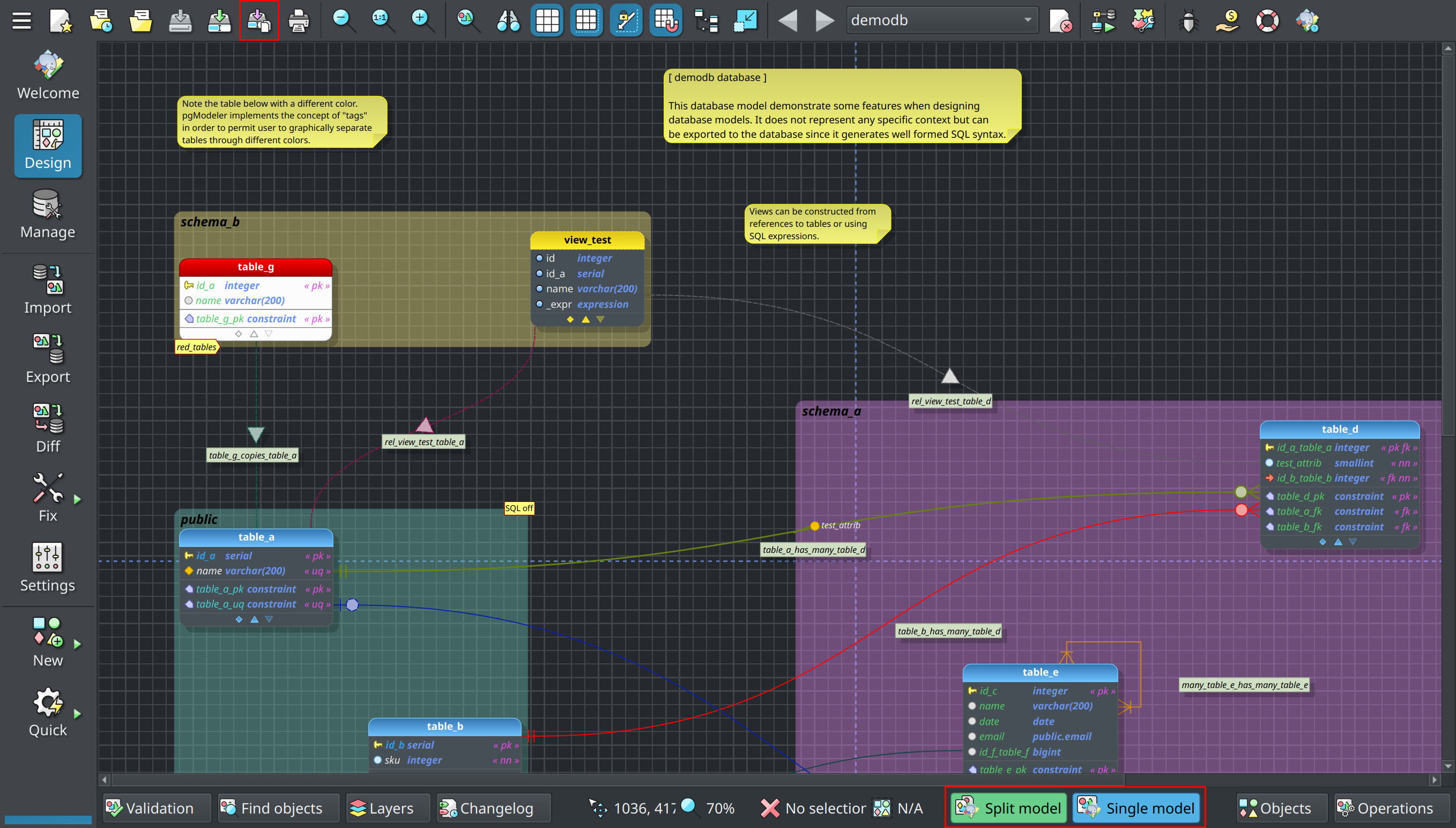
Finally, pgModeler still relies on the classic .dbm files when loading the split database model. In resume, when opening a .sdbm, pgModeler reconstructs the entire database model by parsing the .sdbm and .dbo files creating a temporary .dbm file where all the modifications will be applied during design time. Every time the user saves the model pgModeler automatically updates the split database model definition so it can stay synchronized with the temporary one. To help the user to identify the database model file types that are being handled, pgModeler will now show, at the base of the design area (see the image) the badges Split model for models loaded from .sdbm and Single model for models loaded from .dbm files. When working with split models, both badges are displayed to indicate that pgModeler is taking care of the original .sdbm and the temporary .dbm file created from the loading process of the split model. I still consider this feature experimental, so, any help to improve it is welcome!
SSH tunnel plug-in
An SSH tunnel is a technique widely used to encrypt a connection between a client and a server via SSH application providing a security layer for the connection even in the absence of an SSL certificate. The SSH tunnel plug-in comes as a facility to configure and start SSH tunnels quickly.
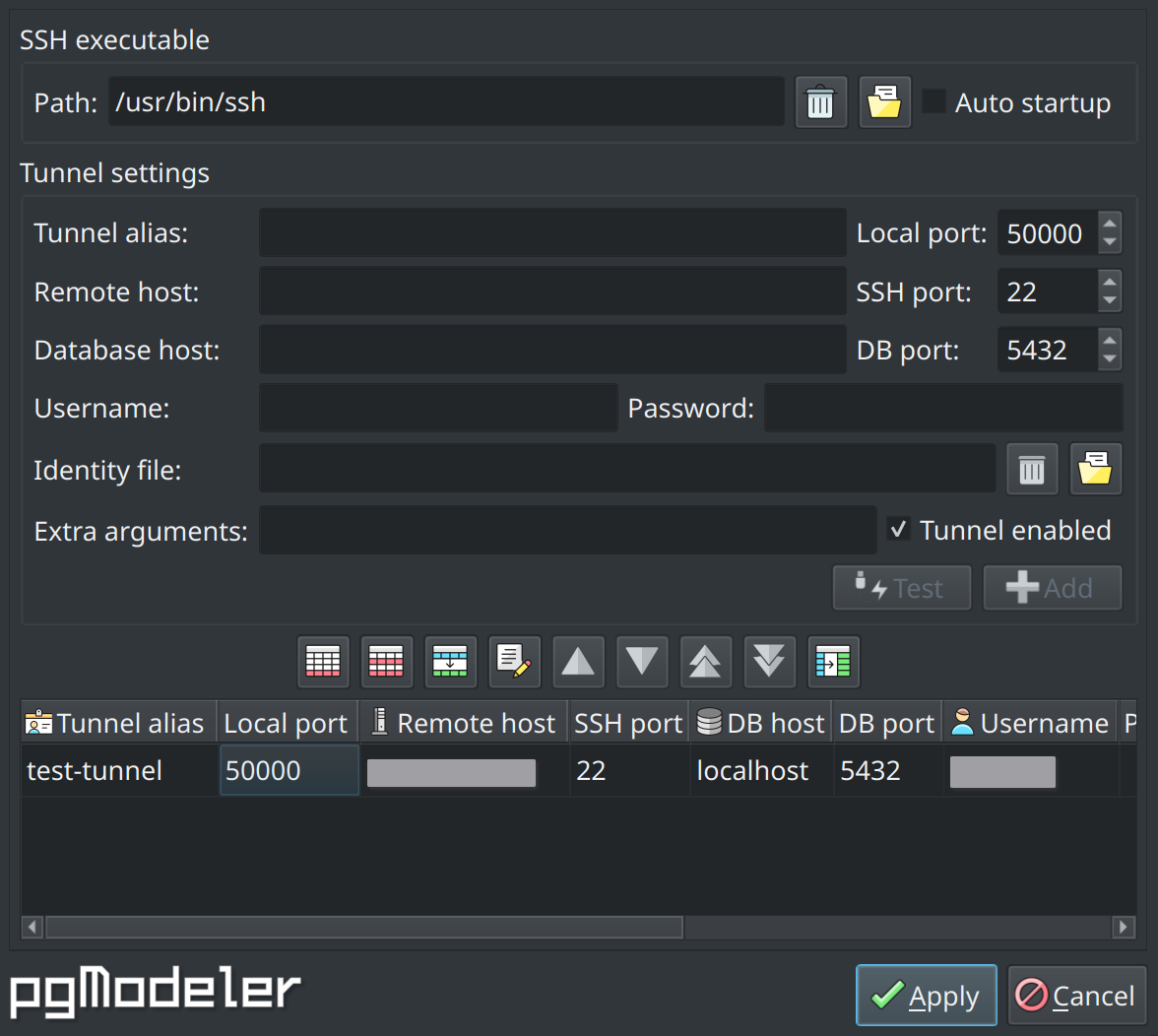
The fields in the form above are described as follows:
-
SSH executable path: the SSH application used to initialize tunnels. Currently, tunnels can be only used with OpenSSH client.
-
Auto startup: indicates if the SSH tunnels must be started during pgModeler's startup.
-
Tunnel alias: a unique identifier for the SSH tunnel.
-
Local port: the local host port number in which the configured tunnel will be started.
-
Remote host: the endpoint IP address or domain name for the SSH tunnel. This is the machine that is ready for SSH connections.
-
SSH port: the listening port in the remote host for SSH connections.
-
Database host: the PostgreSQL server IP or domain name to connect when the SSH tunnel is established. It can be the remote host itself or another machine address that is accessible from the remote host.
-
DB port: the database server listening port.
-
Username: the SSH username of the remote machine.
-
Password: the SSH password of the remote machine. If an identity file is used to connect to the remote host then this will be used as the identity file's security passphrase. Be aware that this field is only a convenience to avoid repeatedly typing the password during the tunnel initialization, use it with extreme care since it is saved as plain text in the settings. Also, ensure that only your user has access to the pgModeler's configuration files since they store sensitive data that can be exploited.
-
Identity file: the file from which the identity (private key) for public key authentication is read. Refer to SSH documentation for more details.
-
Extra arguments: extra arguments that are passed to the SSH executable during tunnel startup. Refer to SSH documentation for more details.
After configuring an SSH tunnel, you have to configure a database connection in such a way to use the tunnel's database host combined with the local port so the encrypted connection can be established correctly. The video below gives a small step-by-step on how to set up both SSH tunnel and database connections that communicate via the tunnel.
Adoption of semantic versioning
For now on, pgModeler will use the Semantic Versioning schema for future releases. The reason behind SemVer is to give a clear idea of how a certain software version only fixes bugs, breaks compatibility somehow, introduces new features that may change deeply the code base, and so on. Thus, firstly, I intended to release patches more quickly without making the development process go through alpha and beta stages when working only with hotfixes, and of course, prepare the users for any compatibility breaking, mainly with database model file specifications which I'm aware is pretty annoying.
So, to give an overview of how SemVer works, I'll first quote the semantic versioning page:
Given a version number MAJOR.MINOR.PATCH, increment the:
- MAJOR version when you make incompatible API changes
- MINOR version when you add functionality in a backwards compatible manner
- PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
Semantic versioning is a really easy concept to follow, and many software developers, including me, already follow it even partially without knowing that. So, taking the pgModeler's use case as an example, now that 1.0.0 is ready, the next one will be a patch release 1.0.1 followed by as many as needed ones to solve the bugs that eventually are discovered in the next months. When starting to work on a minor version, let's say, 1.1.0, I'll adopt pre-releases, or how I like to say, development versions, a.k.a., alpha and beta until acceptable stability is reached for a final release. When the minor version is ready, the cycle of patch releases mentioned before will start over. The same routine will be applied to major version development.
But what changes are to be considered to be allocated in the patch version, minor version, or major version? The answer to this question is: "it depends on each development cycle of a project!". Anyway, for pgModeler, I have the following ideas which, of course, may be evolved. But for now, that's what I thinking of:
-
PATCH versions will be exclusively released in a certain period of time after a MINOR or MAJOR version is released. This way I can provide a fast response to all bug reports.
-
MINOR version will include small UI changes, minor database model file specification changes that are easily fixed via
pgmodeler-cli, and the introduction of new features that don't break anything. -
MAJOR version will be reserved for deep UI changes, database model file specification changes that can't be fixed via
pgmodeler-clior demand manual intervention and new features that may cause compatibility breaking with other components of the tool.
What comes next?
Well, I'll be out for a while to update the docs for pgModeler 1.0.0. Anyway, I'll try my best to provide assistance to everyone on all support channels. Updating the documentation is an enormous and tiring job which consumes a lot of my time, so I ask for a little patience during this period! :)
Let's support this project!?
If you like the work that is being made to create a quality database design tool, please become our sponsor on GitHub. Any open-source project needs financial support to keep the development alive, and this is not different with pgModeler. Go ahead, be a supporter in one of the offered sponsor tiers and receive rewards for being a friend of an open-source project! :D
In addition to GitHub Sponsors, there's an active campaign whose goal is to acquire a new Mac Mini with the new M1 chip. So, if you are a macOS user and think pgModeler can be improved in that platform, please, consider supporting this campaign! ;)
Well, I think I gave a good idea of how pgModeler has changed since the last stable release a year ago. Right? So, now I just want to say a big THANK YOU to everyone that supports me and this project until today. I hope I can keep counting on the community around pgModeler so the development continues to bring us lots of amazing news! ;)
That's it! Please, don't forget to leave your comments below, and remember that bugs and feature requests can be issued on GitHub. Also, to keep up-to-date with all the project's news, follow us on Twitter or join the telegram channel @pgmodeler.
Until next time! :)
hiepxanh
February 1, 2023 at 10:51:15
Amazing work, since the last version, it have a lot of improvement, I follow you since 2 year ago and this is still one of the best application I ever paid. Your work is so amazing. Congratulation version 1.0.0
Raphael Araújo e Silva
February 1, 2023 at 11:11:01
Thank you very much! :)
Add new comment