Oh boy, how lengthy was the year 2021... This, for sure, was the most complicated one for me! A lot of things happened and I almost postponed pgModeler 0.9.4 to 2022, but I gathered all my energies to finish it before the end of this year, and I made it! Thanks to a lot of special people, from my wife and friends to those who I even don't know but take a bit of their time to send me kind messages that only made me keep working to deliver a new pgModeler version.
This last pgModeler launching of 2021 is really special for me! It closes an important chapter in the development of this project and starts another one even more meaningful. Today, the series 0.9.x reached out its end-of-life as I will start working on pgModeler 1.0 next year. So I have a bunch of ideas to put into practice for the next pgModeler generation, and I hope I can make them a reality very soon.
Now, let's focus on what 0.9.4 brings! In this post, I reunited all the key features described in previous publications to give the users an idea of how this version has changed compared to 0.9.3. So, if you were reading the release notes and blog posts you will have no surprise but if you are in the team that skips unstable versions waiting for stable ones, I'm sure that you'll see how the tool evolved since December 2020!
Multiple layers support
The layers support, introduced by pgModeler 0.9.2-alpha, was intended to be used to separate objects in different contexts and quickly hide/display them. This feature was pretty simple and started to receive some suggestions for improvements. The main complaint about layers at that time was the lack of ability to visually identify in which layer an object was in. So, thinking of that situation, we have added the ability to put an object in two or more layers at once, and, additionally to that, pgModeler will now draw rectangles with custom colors around the objects that are part of a certain layer. Besides, we have also included the ability to change the color of the layer names to make this feature fully customizable. The complete result is in the right portion of the image below.
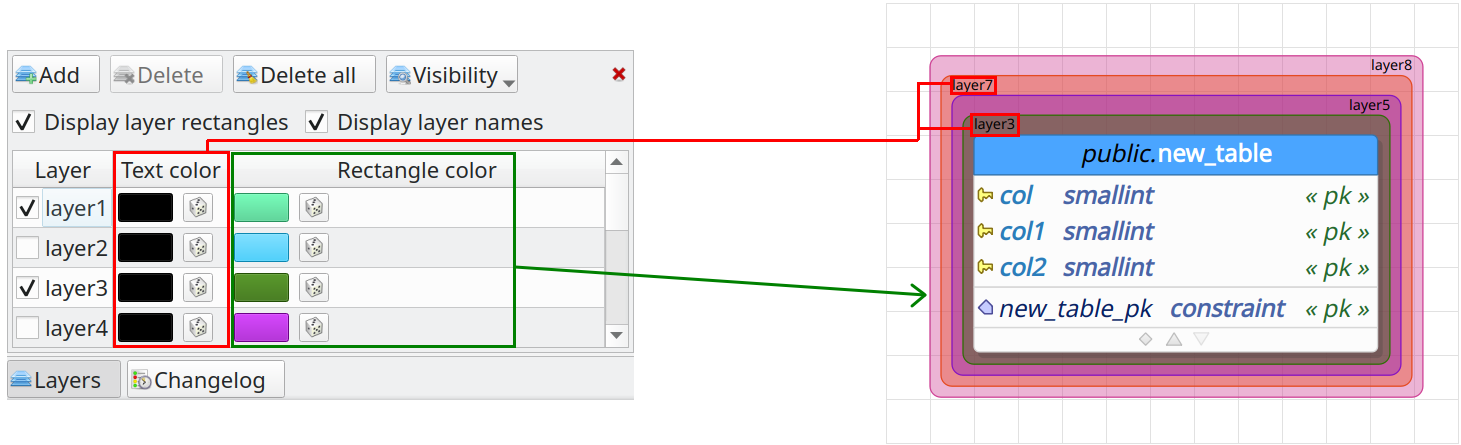
At the left portion of the above image, we have the improved widget that handles all the layers' settings. As you can see, now it's possible to toggle the displaying of layer rectangles and names around the objects, as well as to set up the colors of the elements of the layers. Like in previous versions, the checkboxes aside from the layers' names are used to quickly toggle the visibility of a specific layer. You can quickly toggle the visibility of all layers by clicking the button Visibility and activating the presented actions. In this release, it's also possible to rename the default layer which was not possible in previous versions.
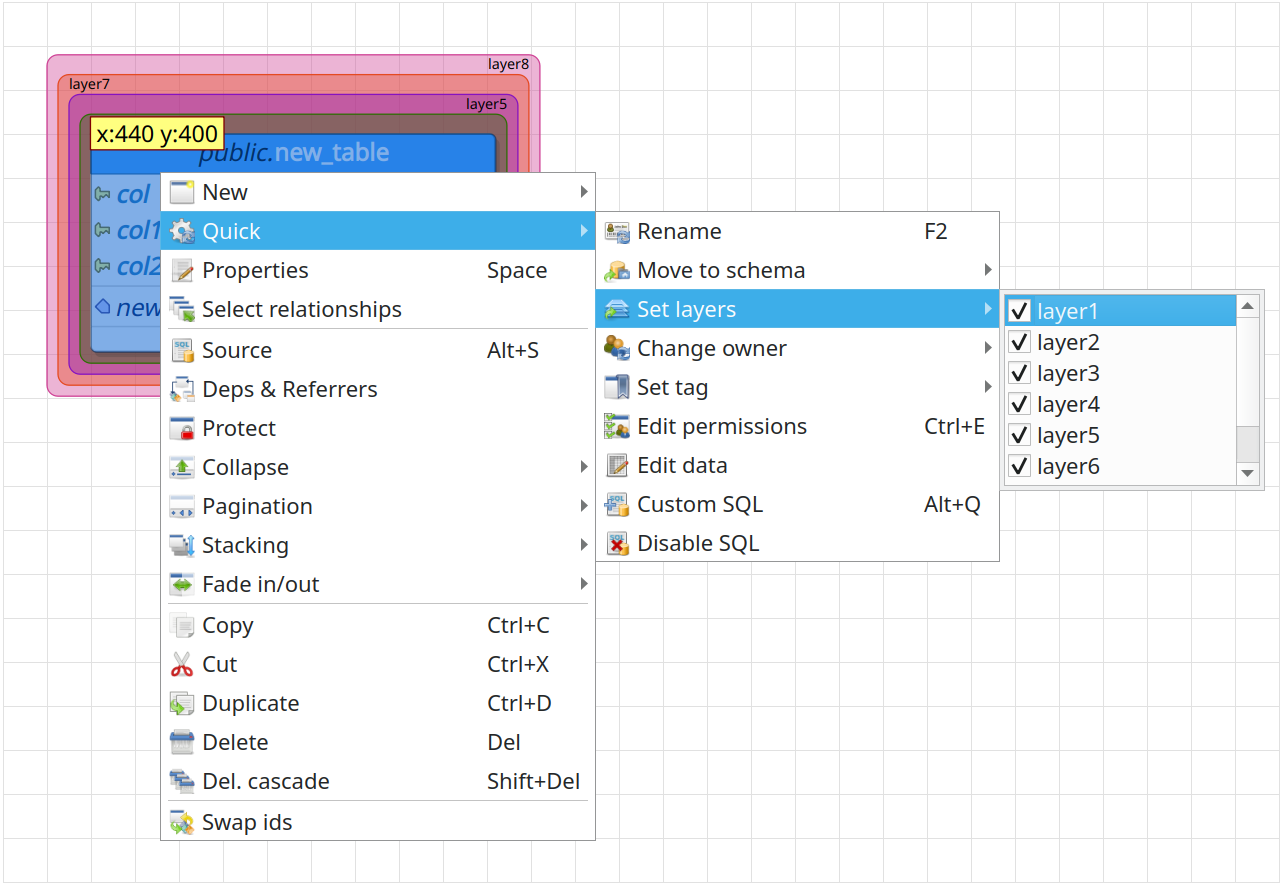
The below image shows that in pgModeler 0.9.4 you can quickly move objects to the desired layers. To do so, just select the graphical objects in the canvas area by using one of the several actions for that purpose, right-click the selection of the objects, and then focus the menu item Quick > Set layers. After that step, a floating listing will be presented where it's possible to define all the layers to where the objects will be placed on. One important thing to mention is that the layers that are common between the selected objects will be checked during the first display of the listing. The layers selection is automatically applied to the selected objects once the listing is hidden.
Metadata handling improvements
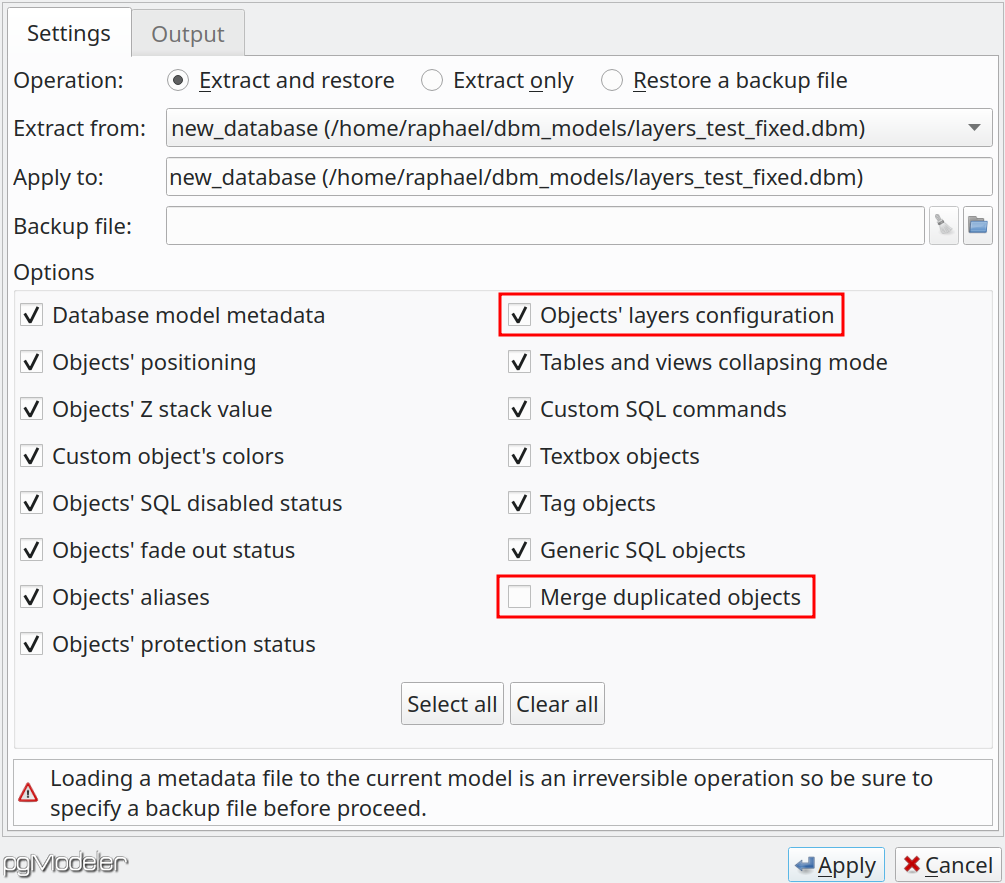
The metadata handling process was improved in order to support the new multiple layers feature. Now it's possible to transfer layers configurations from a model to another by checking the option Objects' layers configuration. Another enhancement done is the ability to merge duplicated textboxes, tags, and generic SQL objects through the option Merge duplicated objects. With the merging option, it's possible to make the mentioned objects kinds in the destination model (the one in which a set of metadata is being applied) be forcibly replaced by the ones presented in a metadata backup file or source database model.
Custom canvas colors
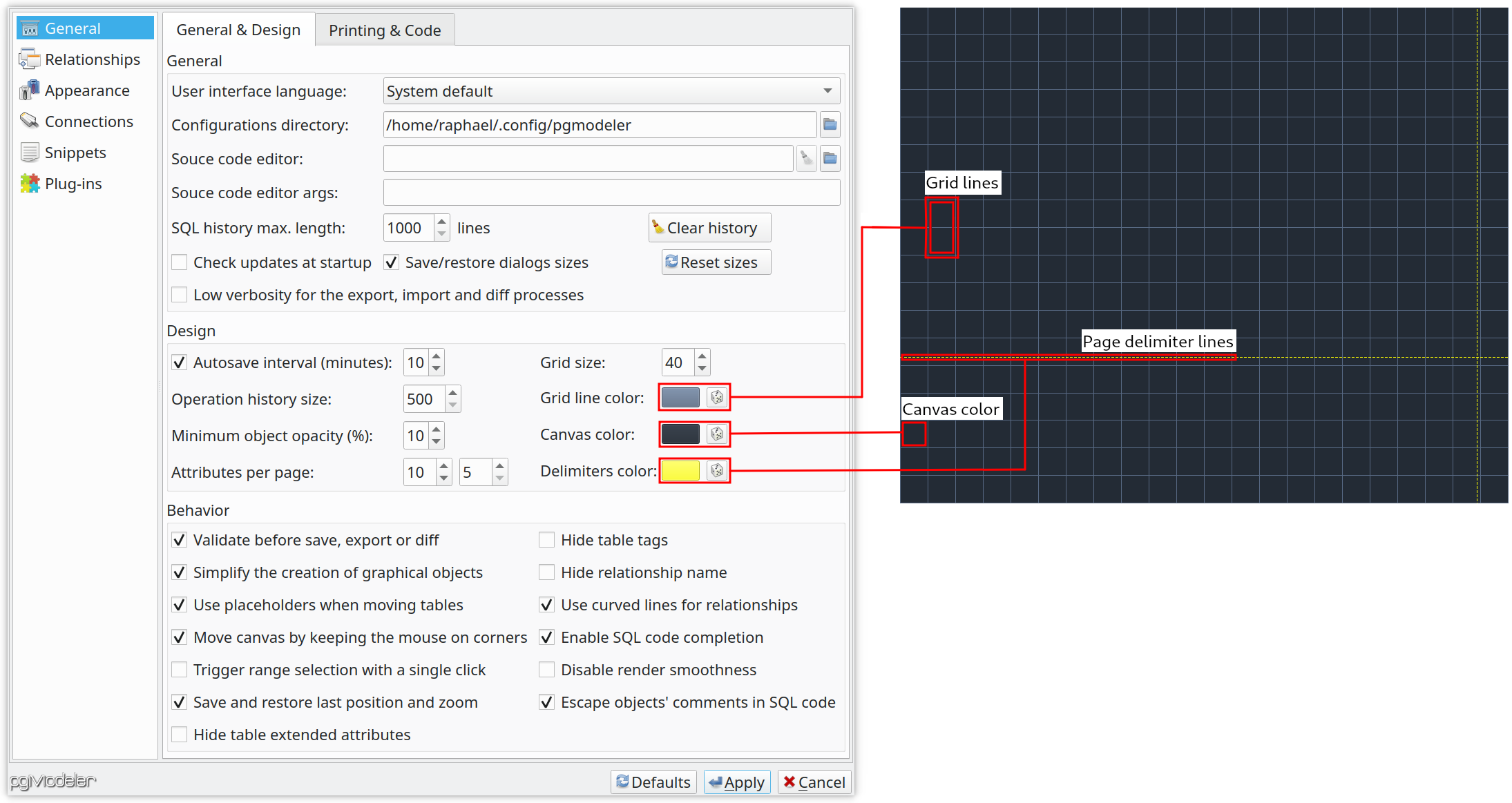
Thinking of user's eyes comfort, we've introduced the custom color for canvas elements like grid line colors, page delimiter line colors. The colors can be configured in the General settings at pgModeler's settings dialog. Once defined the desired color just click Apply so they can be applied to all loaded models. This small improvement is the starting of a series of UI/UX enhancements I'm planning to do to pgModeler so it can be more pleasant to use (in the sense of comfort). Another improvement on the way is the ability to set up custom colors for source code elements so the users can match their system color pattern to pgModeler's color pattern in its different GUI elements.
New attributes for function and procedure
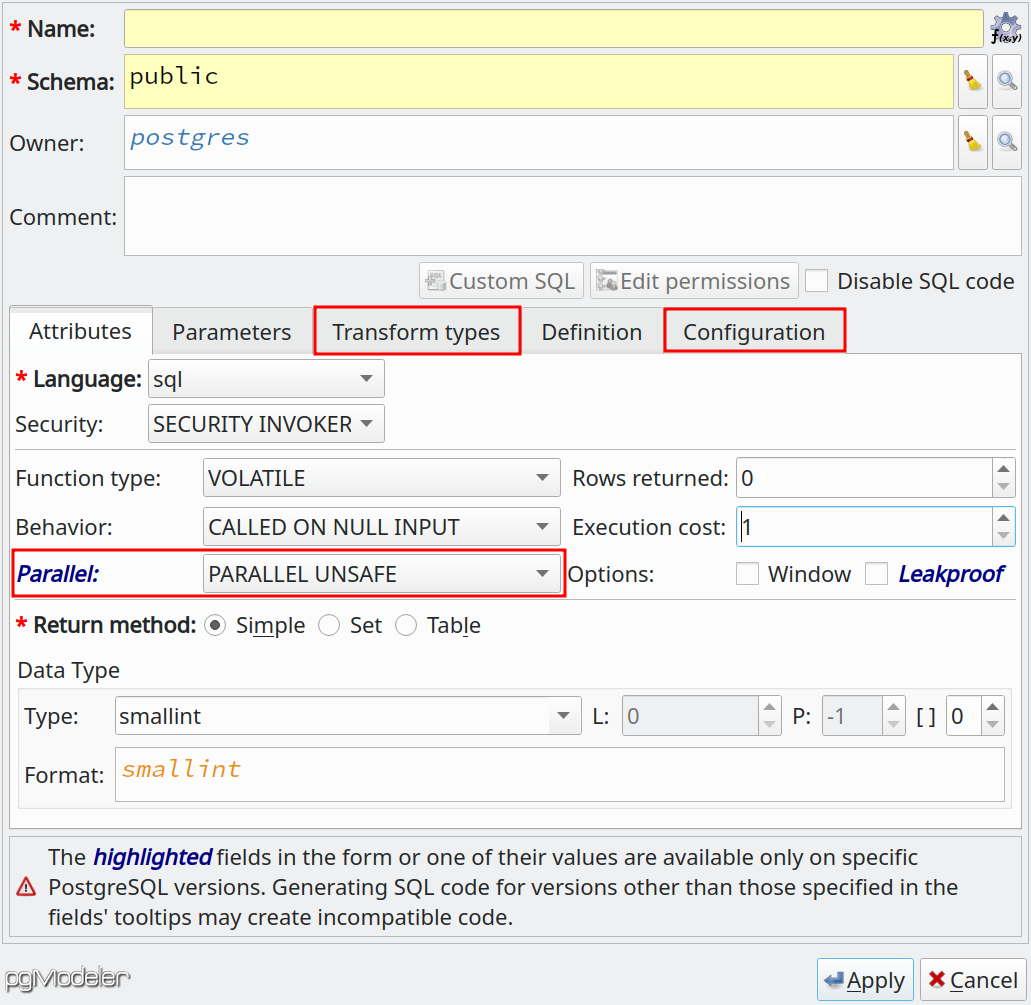
Functions and procedures received support for parallelism settings available since PostgreSQL 9.6 through the attribute PARALLEL SAFE | UNSAFE | RESTRICTED. Another advance in these objects is the support for transform types which list the transforms that must be applied to the function or procedure during an execution. Finally, attending to some old requests, we've added the support for runtime configuration parameters for functions and procedures through SET configuration_parameter = value in these objects' DDL command.
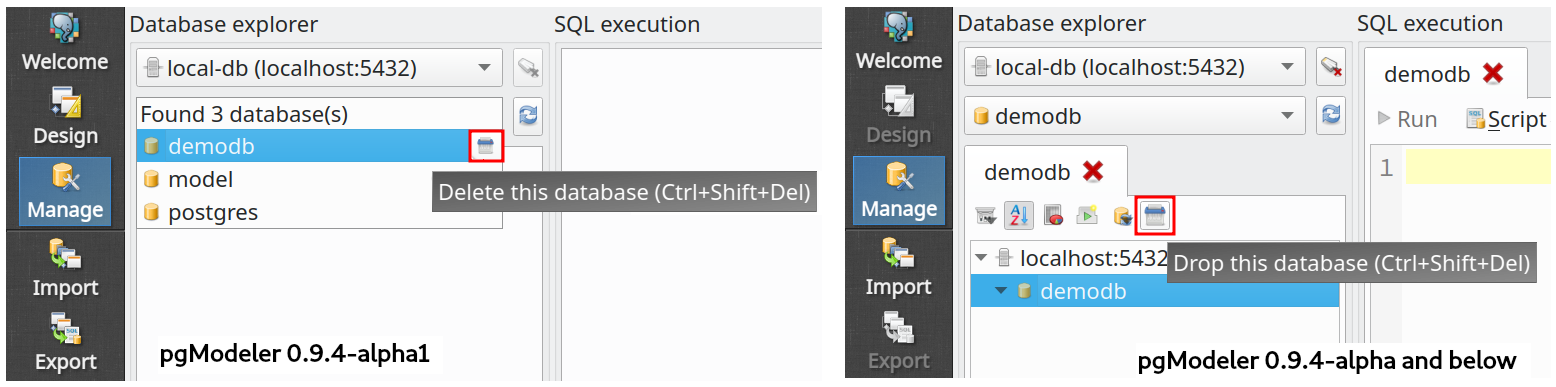
Quickly drop databases
This is an old improvement that I wanted to implement but never found the proper way to do that, until now. This new release allows the user to drop databases quickly just by clicking the button ![]() aside a selected item in the database listing or hitting
aside a selected item in the database listing or hitting Ctrl + Shift + Del. In previous versions, the procedure to drop a database in SQL tool was to browse the database first and then to click the same icon at the top of the database browser widget. The old way to drop databases in GUI was kept in this release but it tends to disappear in the future since it is way more complicated than the new one introduced.
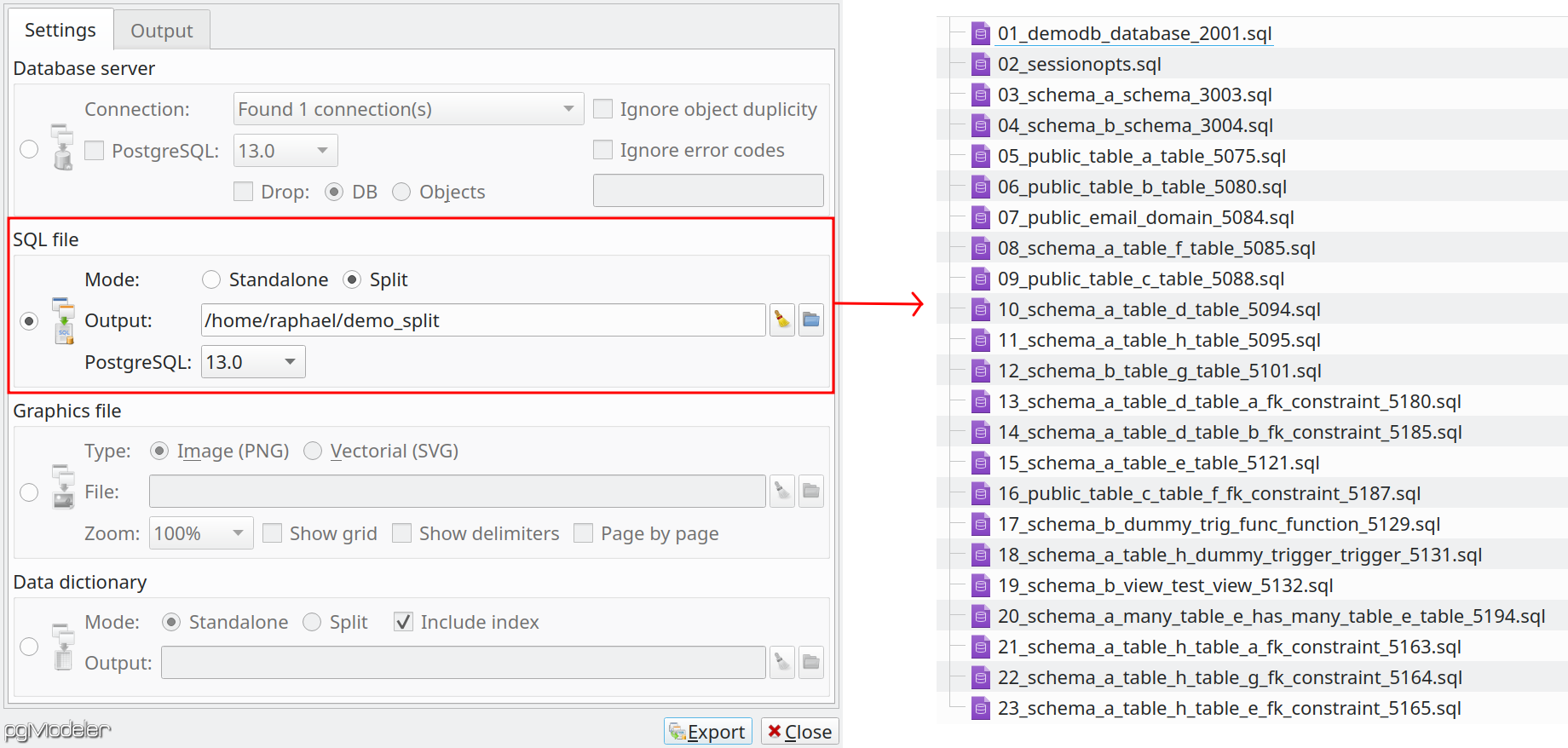
Exporting to split SQL files
Attending to requests, 0.9.4 introduces split export mode. In this mode, instead of generating a single SQL file representing the entire database model, a file is created for each database object. Note that the files are named in such a way to represent the proper order of creation (see below), thus, running the scripts one after another will create the whole database like it was created from a single file. This mode can be useful for custom deployments processes where you need to create objects one by one in the database server while performing any other parallel task needed by your development tool. The pgModeler's command-line interface also supports this new mode, just provide the parameter -sp or --split while using the export operation--export-to-file.
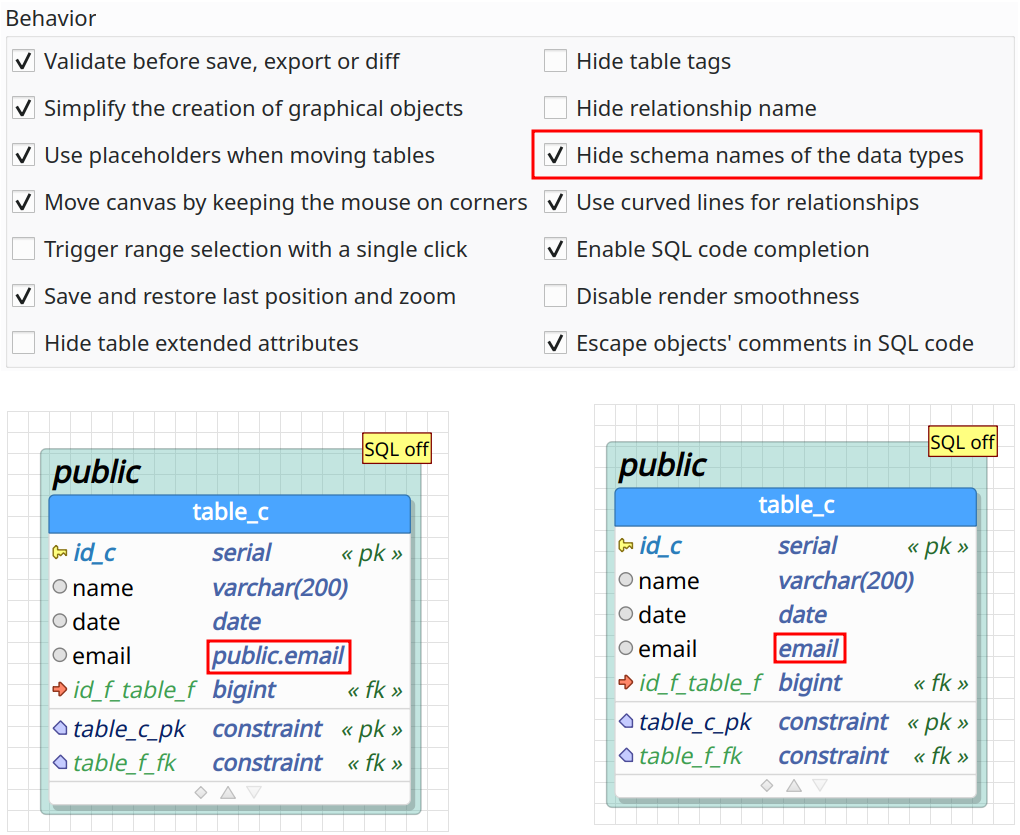
Hide schema names from data types
Another change brought by pgModeler 0.9.4 is the improved user-defined data type handling. In the middle of these enhancements is the ability to toggle the displaying of schema names of user-defined data types used by table columns. This can be adjusted by the option Hide schema names of data types in the group Behavior on the general tab at pgModeler's settings. This is a convenient way to display your database model in a more compact way if you use lots of user-defined types. Note that toggling the schema names only affects the design view, the code generation and other portions of the tool still need to use schema-qualified user-defined data types to avoid conflicts.
Adjust role memberships through diff process
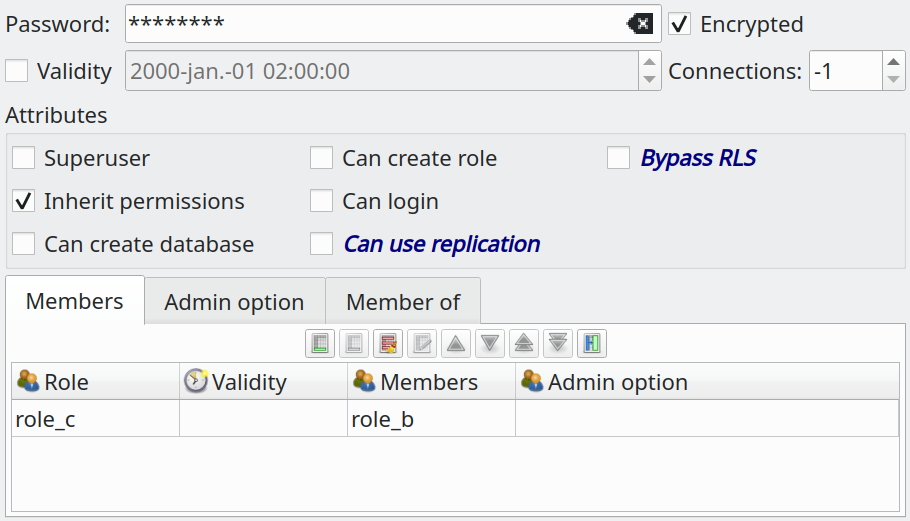
pgModeler now supports the generation of GRANT and REVOKE commands to (re)configure role memberships in the diff process. Basically, you have to use the role editing form to set up the desired memberships of a certain role and then all the magic will be made by the diff. Due to the introduction of this new feature, there was the need to change the role form. The tabs were reordered and some renamed to give better semantics. Additionally, the tab "Member of" needed to be modified in order to make the diff generation more precise.
The tab Members lists the roles that are members of the role being edited, this represents the instruction ROLE role1, role2 .... The tab Admin option lists the roles that will receive the right to grant membership in the handled role to others, this is what the instruction ADMIN role1, role2 ... does. Finally, the tab Member of , in previous versions, was used to configure the roles in which the one being edited was part, generating the instruction IN ROLE role1, role2 .... But in pgModeler 0.9.4-beta, we had to abandon the IN ROLE generation due to some problems it was causing for the generation of diff scripts, so now, when adding roles in this tab pgModeler will simulate the behavior of IN ROLE but in practice, no such code will be generated, instead, the role handled in the form will appear in the instruction ROLE of the ones listed in Member of tab. The only limitation of this change is that the role postgres can't be used for now in the tab Member of since it can't be handled directly by the user in pgModeler.
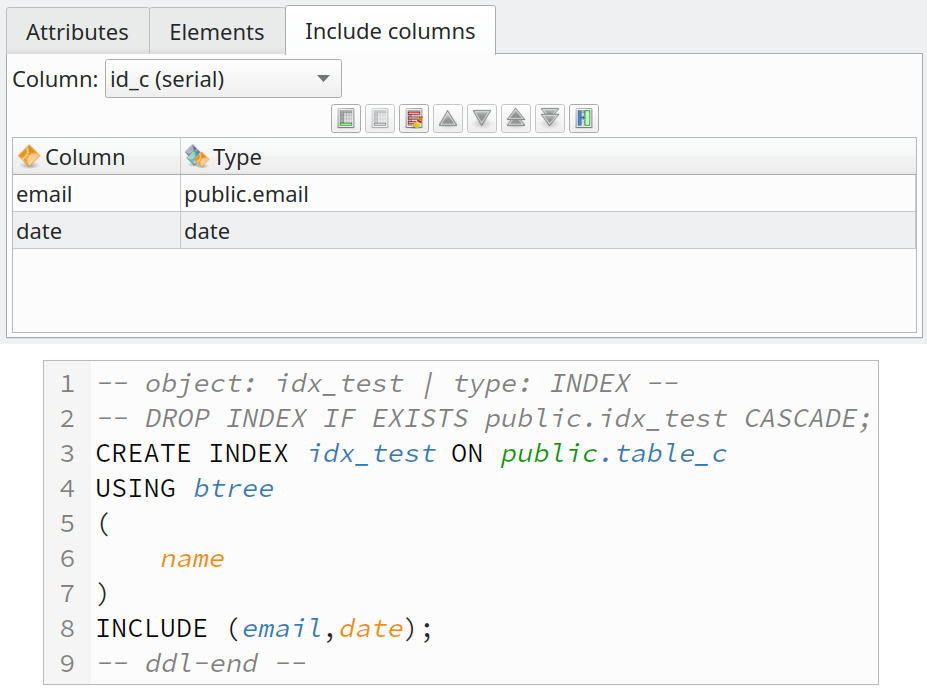
Indexes now support non-key columns
Non-key columns, as stated in PostgreSQL docs, can be used to make effective use of index-only scans, by choosing to create a covering index, which is an index specifically designed to include the columns needed by a particular type of query that is run frequently. Since queries typically need to retrieve more columns than just the ones they search on, PostgreSQL allows one to create an index in which some columns are just "payload" and are not part of the search key. This is done by adding an INCLUDE clause listing the extra columns. This new pgModeler version brought a simple interface to configure non-key columns in an index, as shown below.
This feature opened the path to the possibility to reference view columns in other objects. For now, it's possible to use view columns on their own indexes, but the plan is to allow views to reference columns of each other in order to make the code generation even more powerful. The only downside of this new ability is that pgModeler isn't yet able to keep track of name changes in view columns, so each time a view column name is changed you have to check all objects that use it and make the proper modifications, not forgetting to always validate the model.
pgModeler Schema Editor tool
Due to the need to constantly edit schema files for code generation test purposes, I decided to create my own mini-editor called pgModeler Schema Editor (pgmodeler-se). The idea to create the application pgmodeler-se came from the lack of native support for *.sch on my preferred editor (hello, Kate!). In fact, Kate can handle this type of file with some tweaks here and there but I found it more complicated than creating a small editor from scratch since I had everything I need in pgModeler's codebase.
With this auxiliary tool, an advanced user can manipulate the schema files stored in the schemas folder. You can, for example, change the default SQL/XML code formatting, add extra instructions to the generated code, validate the syntax of the documents, apply automatic indentation, and much more. The application also allows you to tweak the syntax highlighting files (SQL, XML, or SCH) either in the user's local storage or in the pgModeler's installation folder. Of course, this application is not for every user since it may break your pgModeler installation if some wrong edition is made on any file that it handles. So, use it with caution! :)
Here comes pgModeler 1.0!
It's no secret that, for a long time, I want to start to work on pgModeler 1.0. In order to shape the codebase into the final form I want for 1.0, I made some important changes in the folders in the source code root. The first change was to rename all the remaining icons from Portuguese to English and perform the needed changes in the source code. Some unused or outdated files were removed too.
The libraries' subprojects were moved to the folder libs and some of them were renamed to give better semantics. The libpgmodeler now it's called libcore, libpgmodeler_ui was renamed to libgui, and libobjrenderer received the new name libcanvas. This rearrange was applied to executables subprojects as well. Now there's a dedicated subfolder called apps which store all executables subprojects, thus, the main executable subproject was renamed from main to pgmodeler, the crashhandler is now pgmodeler-ch, the command-line interface subproject main-cli was renamed to pgmodeler-cli, and the pgmodeler-se is the new executable subproject related to the pgModeler Schema Editor application.
Finally, the last change made in the source code root was to create a folder called assets and store in it all the files that are deployed with libraries and executables, for example, code schemas, language settings, configuration files, and database model samples. These changes don't affect you if you just compile and use pgModeler. But if you're a plug-in developer or a package maintainer, or even have a custom code running over pgModeler's code you may need to review your build process in order to check if something is broken after such changes.
Miscellaneous
Some other enhancements and fixes that are worth mentioning:
-
In addition to the multiple layers support, pgModeler will now use a compatibility routine when loading models created in previous versions (0.9.3 and below) in order to avoid losing information about layers and active layers.
-
The database model loading process was also fixed in such a way that the changelog used during the diff process is correctly retrieved from XML code.
-
In order to reflect the multiple layers support for older models the pgModeler's command-line interface will now rename the attribute
layertolayersso they can be properly adjusted to 0.9.4. -
Attending to some requests the minimum size of the main window was adjusted to 640x480 so it can fit on smaller screens avoiding blocking access to some UI components that could prevent the proper usage of the tool.
-
The option
Truncate before alter columnsin the diff process was removed since its use is discouraged and dangerous in some situations due to the risk of dropping objects that aren't expected to be removed. -
There were important fixes in the SQL code generation in such a way to avoid malformed code for triggers and functions based on
internallanguage. -
The addition of new metacharacter to schema micro-language. The metacharacter
$hstranslates to hash character#,$psis for percentage sign%,$atdenotes@,$msmeans money sign$, and$dsis converted to a special data separator character•. -
Added the option
--forceto the mime type handling operation on the command-line tool. This option can be used in certain circumstances where the CLI can't determine if the file association is correctly installed/uninstalled. -
In the data manipulation form, the behavior of column click was changed. Now, the sorting operation over the column is triggered by holding control and clicking it. If the user clicks a column without holding the control key all the items on that column will be selected instead of performing a sorting.
-
The crash handler application and bug report form (inside GUI) was patched in such a way to capture the last modified model opened. Previously, the model captured was always the last one focused and not necessarily the one that caused the unexpected crash or bug on the tool, which could not help to identify the problems reported by the users.
-
The database import is in constant enhancement, this time a crash when importing inheritance relationships was eliminated. Additionally, the data types related to extensions are now being properly configured and associated with columns.
-
A malformed SQL code generation when configuring
timestamptzwas fixed. -
Fixed a bug that was causing all layers to be active even if there were some inactive (invisible) layers when adding a new one.
-
The command-line interface does not crash anymore when running the diff operation in which a database model is used as input.
-
The
pgmodeler-clitool now has a fix step to reconfigure roles membership considering the deprecation of the previous behavior of "Members of". -
Attending some users' requests now there's the possibility to toggle update notifications regarding alpha and beta versions. This behavior can be adjusted in general settings.
-
In the database explorer widget (in SQL tool) the collapsing state of the objects' tree is preserved even after refreshing the whole tree due to creation and delete operations.
-
Now, when renaming an object through the object rename widget, the name field comes pre-filled with the object's name in the first show when a single object is selected for renaming. The object rename widget can be triggered by selecting objects in the design view and hitting
F2. -
Due to the new roles membership configuration feature, you can now swap cluster level object ids (roles and tablespaces) in the object swap form when the objects to be swapped are of the same kind.
-
In order to be PostgreSQL compliant, the default match type of foreign-key constraints was changed to
MATCH SIMPLE. -
The database model changelog widget now displays the first modification date.
-
A crash in the swap objects widget was fixed when the user tried to swap objects using arrow keys.
-
The diff form was patched in such a way to allow the use of Return/Esc keys to respectively run the diff and close the dialog.
-
The code generation of aggregates was fixed and now the DDL command is properly created when these objects use functions that contain parameters in which data type have spaces (
double precision,character varying, and so on). -
Fixed a segmentation fault that could happen when the user tried to change the number of parameters of a function already associated with an aggregate.
-
This new version brings the experimental support for timescaledb in reverse engineering. So, now pgModeler is capable of generating models from databases that make use of that PostgreSQL extension without major issues.
-
Added extra PostGiS data types to PgSQLType in order to make the importing of databases using this extension more precise.
-
Added the built-in type pg_lsn in order to make databases using timescaledb extension to be imported correctly.
-
Adjusted the catalog query filters in the diff dialog to retrieve system and extension objects according to the checkboxes
Import system objectsandImport extension objects. -
Adjusted the reverse engineering in such a way that the table children will follow the SQL disabled state of their parent tables.
-
Allowing the use of commas in enumeration type labels.
-
Improved the output of model fix operation in the command-line interface.
-
Improved the model validation process in order to set PostGiS extension a default comment when automatically creating it, avoiding false-positive results in diff process.
-
In the widget used to configure PostgreSQL data types, type qualifiers like length, precision, interval, and some others will be disabled for types used in the following objects: parameters, aggregates, transforms, casts, operators.
-
Fixed the catalog query that lists policies in the reverse engineering process.
-
Added a minor workaround in reverse engineering in order to treat the
anypseudo-type correctly. -
Fixed a crash when importing domains with long constraint expressions.
-
Fixed the broken SQL generation for tables with columns/constraints disabled.
-
Fix the name of the checkbox related to updates checking to avoid breaking the building when enabling
NO_UPDATE_CHECKviaqmake.
New generation, new logo!
Since I was starting to think of pgModeler 1.0, I had the desire to give a fresh-looking to the project's logo. So, since the end of 2019, I was working on several logo candidates and I finally came up with the one below. I really enjoyed its clean-looking and lighter colors, so I decided to stick with it for pgModeler 1.0! I'm also in the process of selecting and producing new icons to be used in the tool as part of the UI improvements I want to give to the project in this new phase. So, from now on, this will be the new official logo of this project!

Well, as always, I would like to thank everyone that helped this project to reach an upper level of maturity. I'm really happy to see how far pgModeler has gone and excited to start working on its next generation. But first, I need to go out on a vacation to recharge my batteries and in the hope to get back with a lot of new ideas.
Until mid-January, we'll have the updated version of the docs contemplating all the new features introduced by 0.9.4. So, for now, feel free to contact me with any questions regarding this new release, or just to say "Hi"! :)
I wish Merry Christmas and a new year of hope, health, and love to everyone!
Until next time! ;)
Danillo Carvalho
December 17, 2021 at 10:45:34
Bom dia, quero passar pra agradecer e parabenizar pelo programa, utilizo a versão anterior e tem sido de grande ajuda. Acho muito bacana que esse programa seja desenvolvido por um brasileiro, nunca encontrei outro programa que trabalhasse com o postgresql, desejo longa vida para esse projeto. Parabéns e felicidades!
Raphael Araújo e Silva
December 17, 2021 at 11:53:53
Muito obrigado pelas palavras, Danillo! Fico extremamente feliz que o pgModeler tem sido de grande ajuda para você. Esse é o meu objetivo à frente desse projeto! :)
Trần Quang Hiệp
December 18, 2021 at 00:27:13
Thank you so much, mary christmas, after these year, Postgres will never be completed with your software, your work is so amazing. Helping people like us to create amazing product. Best wish to you :p
Raphael Araújo e Silva
December 18, 2021 at 16:45:50
Thank you very much! Merry Christmas for you and your family too! ;)
Add new comment