Hey there! Here we're again announcing another pgModeler release. This time I'm even more excited because we reached the beta stage which means that the stable 1.0.0 is practically in its final shape. So from now on, until its definitive launching, I'll work exclusively on bug fixes. New features will be added exclusively to the paid version... I'll explain why further in this post.
Despite the delay in launching this first beta which should be in the last month, I managed to implement almost all the things I intended for it. This version brings a critical breaking change that may disappoint a few users but it was needed so I could save energy in keeping legacy code and focus on new and exciting features from now on. So, with no more delay, let's see what pgModeler 1.0.0-beta introduces!
Before you start using 1.0.0-beta!
If you installed pgModeler 1.0.0-alpha before using 1.0.0-alpha or 1.0.0-beta you may get the error "Error while interpreting XML buffer at line 0 column 0. Message generated by the parser: No declaration for attribute partial-match of element group." right before pgModeler quits during its startup.
This error occur due to an attribute of the syntax highlight files which was dropped. The solution is to manually erase the files *-highlight.conf in your user's local storage where pgModeler settings are saved: /home/(user)/. config/pgmodeler-1.0 (Linux),C:\Users\(user)\AppData\Local\pgmodeler-1.0 (Windows), /Users/(user)/Preferences/pgmodeler-1.0 (macOS). After erasing the files, start pgModeler again so the erased files can be created again by the tool.
Goodbye PostgreSQL 9.x support!
Yes, pgModeler does not support PostgreSQL 9 anymore. This move was delayed a lot of times since the launching of PostgreSQL 10, so I decided that during the development of pgModeler 1.0.0 the support for discontinued versions of the RDBMS would be completely dropped. Honestly, it was a kinda relief for me because keeping a code base that embraces PostgreSQL 9.0 to 15 is a huge challenge because there are lots of syntax nuances that I need to keep track of which causes an increase in the code complexity. Furthermore, PostgreSQL 9.x is gradually being ditched while modern versions are being quickly adopted, so it doesn't make sense to make pgModeler support such an old version of the database system since it is not maintained anymore by the community.
Being said that, pgModeler 1.0.0-beta will now refuse to connect to PostgreSQL servers below version 10. If you're negatively affected by this project decision, you still have at your disposal pgModeler 1.0.0-alpha1, or if you prefer a stable release, 0.9.4 is still here until 1.0.0 stable is ready. Anyway, keep in mind that using older versions of the database system and even of pgModeler may lead you to security issues and critical bugs that may cause you a lot of headaches, so always upgrade your PostgreSQL (and pgModeler) installation when possible! ;)
Improved magnifier tool
The magnifier tool is one of the least known features of pgModeler but can help you a lot when working with densely populated database models. The magnifier tool, triggered by F9 in this new version, helps you to navigate through a zoomed-out model while highlighting (in normal zoom factor) a small portion of the model where the mouse cursor is while you can interact with the objects in the magnified area as you would do in the entire database model in a normal view, like selecting multiple objects and even triggering the popup menu to handle objects.
New objects in the data dictionary
The data dictionary received some patches and now is capable of adding information about indexes, triggers, and sequences that is related to a certain table, foreign table, and view. This improvement makes the generated dictionaries more detailed enriching the database documentation. These objects are automatically added to the tables' dictionaries, so there's no way to avoid the generation of their information grid. Anyway, I'm already planning to add a switch in the data dictionary generation that toggles the inclusion of these objects in the grids, for those who maybe think that the data dictionaries would be polluted with extra (and somehow unneeded) information. Just leave your thoughts in the comments sections so I can adjust this feature in the next release.
Generate split SQL code in CLI and GUI
Since pgModeler 0.9.4-alpha1 pgModeler offers the generation of split SQL code. In 1.0.0-beta, this feature was improved in such a way as to expand the way code is generated for each object. This feature already existed for some time and was "hidden" in the source code visualization form. After some users' requests, I've made some patches and included the code generation mode in CLI and GUI export operations. The purpose of this feature is to generate the whole chain of SQL code that correctly creates a single object. This is useful mainly in test environments or if the user needs to deploy SQL code in a different way than pgModeler. There are three code generation modes: Original, Original + dependencies' SQL, and Original + children's SQL. Below, all three modes are exemplified in the source code preview form.
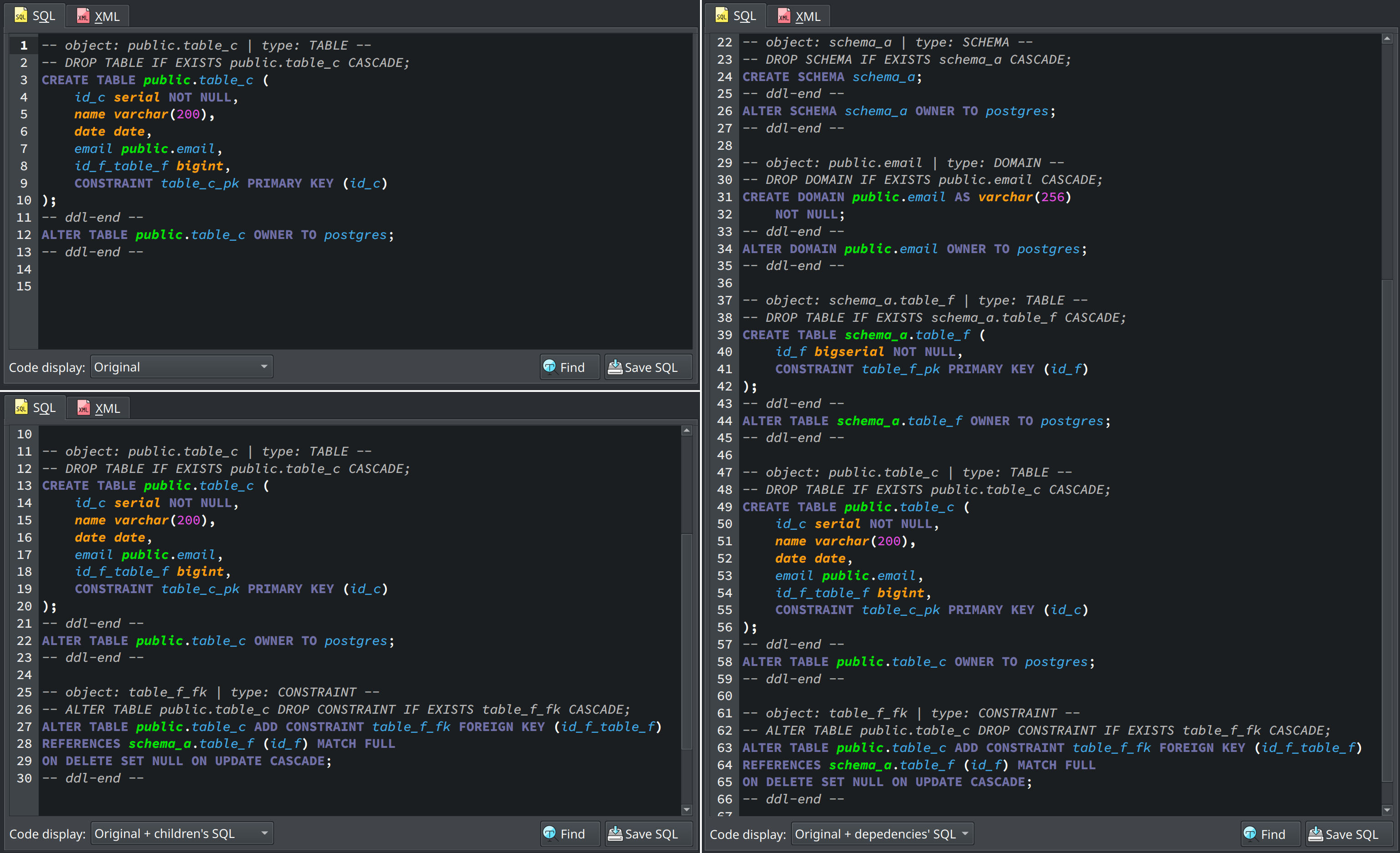
The Original mode, as the name suggests, generates only the original SQL code of a single object without any additional code attached to it. Original + dependencies' SQL generates the original code including all dependencies needed to properly create an object. Now, Original + children's SQL generates the original code including all children's SQL code. This last option is used only for schemas, tables, foreign tables, and views.
In the image below, the same options are displayed in the model export form. You can select the code export mode by checking the option Split, which causes the export process to save the SQL code of the objects in separated files, each one per object, and taking into account the export mode selected in the combo box.
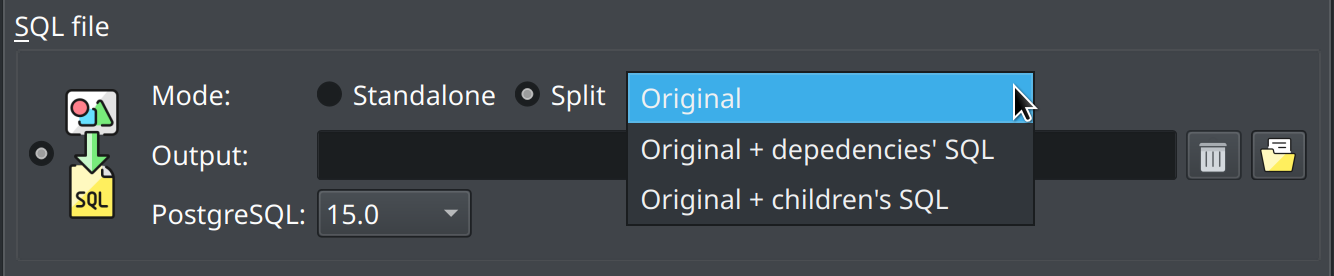
Now, in the command-line interface, the split code generation differs slightly from the GUI. First, you have to specify the output directory through --output, use the export to file operation --export-to-file, turn on the split code generation via --split parameter, and then adjust the code generation using --dependencies or --children. If none of --dependencies or --children is specified then the code generation defaults to Original like in GUI.
SQL file export options: -sp, --split The SQL file is generated per object. The files will be named in such a way to reflect the correct creation order of the objects. -ds, --dependencies Includes the object's dependencies SQL code in the generated file. (Only for split mode) -cs, --children Includes the object's children SQL code in the generated file. (Only for split mode)
Below are some examples of how to call the CLI correctly when using the split code generation:
pgmodeler-cli --export-to-file -if demo.dbm -of /home/user/demo_split --split
pgmodeler-cli --export-to-file -if demo.dbm -of /home/user/demo_split --split --dependencies
pgmodeler-cli --export-to-file -if demo.dbm -of /home/user/demo_split --split --children
Miscellaneous
This version brings 30 changelog entries, between improvements and bug fixes in several parts of the tool. You can check the complete list of changes here, anyway some extra key changes/fixes are described below:
- [New] Added an info message in the FindReplaceWidget reporting the search status (not found, cycle search, replacements made, etc).
- [New] Added a text search widget in SourceCodeWidget.
- [Change] Tab order adjustments in several forms and widgets.
- [Change] pgModeler CLI menu and messages fixed/improved.
- [Fix] Fix a crash in macOS when right-clicking a blank portion of the canvas when there are objects selected.
- [Fix] Fixed a bug in BaseObject::isValidName that was not considered valid a name in the format schema."object".
- [Fix] Fixed the diff generation for materialized views.
- [Fix] Fixed a bug in CLI that was not correctly fixing domains in models created in 0.8.2.
- [Fix] Minor fix in standalone connection dialog to alert the user about unsaved connection configuration.
- [Fix] Minor fix in ConnectionsConfigWidget to avoid adding connections with duplicated aliases.
Exclusive features for paid versions
Like any other open-source project, pgModeler needs financial support, that's no secret! This project lives until today thanks to everyone who helped with suggestions, criticisms, and specially those who believe in its potential and put their money into it. This kind of recognition that makes me work on it since 2006. So, thinking of some kind of reward for the financial supporters, I'll start to work on exclusive features for the paid version of the tool. The first ones will debut still in 1.0.0-beta1.
Of course, nothing will change for the users that compile pgModeler themselves, since I'll keep working on bug fixes and new features normally as I do until today. The idea is to create exclusive features using the plug-in interface without the need to maintain two code bases, one for the community version and another for the paid version. I'll provide more details in the next releases. :)
pgModeler is on GitHub Sponsor, let's help!?
If you like the work that is being made to create a quality database design tool, please become our sponsor on GitHub. Any open source project needs financial support to keep the development alive, and this is not different with pgModeler. Go ahead, be a supporter in one of the offered sponsor tiers and receive rewards for being a friend of an open source project! :D
Well, that's it! I hope you enjoy this new version. Feel free to let your considerations about this new pgModeler in the comments section. Bugs and feature requests can be registered on GitHub. Don't forget to follow the project on Twitter to stay up-to-date with the news about it!
Until the next release! ;)
Add new comment